Lesson: Introduction to Collections 2
The Set Interface
Set은 중복 요소를 포함할 수 없는 Collection입니다. 이는 수학적 집합 추상화를 모델링합니다. Set 인터페이스는 Collection에서 상속된 메서드만 포함하며, 중복 엘리먼트가 금지된다는 제한을 추가합니다. 또한 Set은 equals와 hashCode 연산의 동작에 대해 더 강력한 계약을 추가하여, 구현 타입이 다르더라도 Set 인스턴스를 의미 있게 비교할 수 있게 합니다. 두 Set 인스턴스가 동일한 엘리먼트를 포함하면 두 인스턴스는 동일합니다.
Java 플랫폼에는 세 가지 범용 Set 구현이 포함되어 있습니다: HashSet, TreeSet, 그리고 LinkedHashSet. HashSet은 엘리먼트를 해시 테이블에 저장하며, 가장 성능이 좋은 Set 인터페이스 구현체입니다. 그러나 반복 순서에 대한 보장은 없습니다. TreeSet은 엘리먼트를 red-black 트리에 저장하며, 엘리먼트를 값에 따라 정렬합니다. 이는 HashSet보다 상당히 느립니다. LinkedHashSet은 연결 리스트를 통해 해시 테이블로 구현되어 있으며, 엘리먼트를 삽입된 순서대로 정렬합니다. LinkedHashSet은 HashSet이 제공하는 불특정하고 일반적으로 혼란스러운 순서에서 클라이언트를 구제하며, 비용은 약간 더 높습니다.
"반복 순서에 대한 보장은 없습니다"는 HashSet이 엘리먼트를 저장할 때 엘리먼트들이 특정한 순서로 저장되지 않으며, 엘리먼트들을 반복(iterate)할 때 엘리먼트들이 삽입된 순서나 어떤 정렬 기준에 따라 순서대로 나오지 않는다는 의미입니다. 즉, HashSet을 사용하면 엘리먼트들이 무작위 순서로 나올 수 있으며, 엘리먼트들이 삽입된 순서나 특정한 순서에 따라 나오지 않기 때문에 반복할 때마다 순서가 일관되지 않을 수 있습니다.
다음은 간단하지만 유용한 Set 인터페이스 관용 코드입니다. Collection c가 있고 동일한 엘리먼트를 포함하지만 모든 중복 항목이 제거된 다른 컬렉션을 만들고 싶다고 가정합니다. 다음 한 라인으로 이 작업을 수행할 수 있습니다.
Collection<Type> noDups = new HashSet<Type>(c);
이는 중복을 포함할 수 없는 Set을 생성하여 동작합니다. 처음에는 c의 모든 엘리먼트를 포함합니다. 이는 The Collection Interface 섹션에서 설명한 standard conversion constructor를 사용합니다.
또는 JDK 8 이상을 사용하는 경우, aggregate operations를 사용하여 쉽게 Set으로 수집할 수 있습니다:
import java.util.Arrays;
import java.util.HashSet;
import java.util.Set;
import java.util.List;
import java.util.stream.Collectors;
public class AggregateOperationsExample {
public static void main(String[] args) {
// Collection c 생성
List<String> c = Arrays.asList("apple", "banana", "apple", "orange");
// aggregate operations를 사용하여 Set으로 수집
Set<String> set = c.stream().collect(Collectors.toSet());
// Set의 내용 출력 (중복 요소는 제거됨)
set.forEach(System.out::println);
}
}
위 코드에서 c.stream().collect(Collectors.toSet())는 스트림과 aggregate operations를 사용하여 c의 엘리먼트를 중복 없이 Set으로 수집합니다.
다음은 names 컬렉션을 TreeSet에 누적하는 약간 더 긴 예제입니다:
import java.util.Set;
import java.util.TreeSet;
import java.util.stream.Collectors;
import java.util.List;
import java.util.Arrays;
class Person {
private String name;
public Person(String name) {
this.name = name;
}
public String getName() {
return name;
}
}
public class TreeSetExample {
public static void main(String[] args) {
// 사람들의 Collection 생성
List<Person> people = Arrays.asList(
new Person("John"),
new Person("Alice"),
new Person("Bob"),
new Person("Alice"),
new Person("Eve"),
new Person("Charlie")
);
// aggregate operations를 사용하여 TreeSet으로 수집
Set<String> set = people.stream()
.map(Person::getName)
.collect(Collectors.toCollection(TreeSet::new));
// TreeSet의 내용 출력 (중복 요소는 제거되며, 정렬됨)
set.forEach(System.out::println);
}
}
위 코드에서 people.stream().map(Person::getName).collect(Collectors.toCollection(TreeSet::new))는 스트림과 aggregate operations를 사용하여 people 컬렉션의 이름을 중복 없이 정렬된 TreeSet으로 수집합니다. TreeSet은 엘리먼트를 알파벳 순서로 정렬합니다.
다음은 중복 엘리먼트를 제거하면서 원래 컬렉션의 순서를 유지하는 첫 번째 관용 코드의 약간 변형된 버전입니다:
Collection<Type> noDups = new LinkedHashSet<Type>(c);
다음은 앞서 언급한 관용 코드를 캡슐화하여 전달된 제네릭 타입과 동일한 제네릭 타입의 Set을 반환하는 제네릭 메서드입니다.
public static <E> Set<E> removeDups(Collection<E> c) {
return new LinkedHashSet<E>(c);
}
Set Interface Basic Operations
size 연산은 Set의 엘리먼트 개수(set의 기수)를 반환합니다. isEmpty 메서드는 예상대로 작동합니다. add 메서드는 지정된 엘리먼트를 Set에 추가하고, 해당 엘리먼트가 이미 존재하지 않는 경우 true를 반환합니다. 마찬가지로, remove 메서드는 지정된 엘리먼트가 Set에 있는 경우 해당 엘리먼트를 제거하고, 해당 엘리먼트가 존재했는지를 나타내는 boolean 값을 반환합니다. iterator 메서드는 Set에 대한 Iterator를 반환합니다.
다음 프로그램은 아규먼트 리스트에 있는 모든 고유 단어를 인쇄합니다. 이 프로그램은 두 가지 버전이 제공됩니다. 첫 번째는 JDK 8 aggregate 작업을 사용합니다. 두 번째는 for-each 구문을 사용합니다.
Using JDK 8 Aggregate Operations:
import java.util.*;
import java.util.stream.*;
public class FindDups {
public static void main(String[] args) {
Set<String> distinctWords = Arrays.asList(args).stream()
.collect(Collectors.toSet());
System.out.println(distinctWords.size()+
" distinct words: " +
distinctWords);
}
}
Using the for-each Construct:
import java.util.*;
public class FindDups {
public static void main(String[] args) {
Set<String> s = new HashSet<String>();
for (String a : args)
s.add(a);
System.out.println(s.size() + " distinct words: " + s);
}
}
이제 프로그램의 두 버전 중 하나를 실행하십시오.
java FindDups i came i saw i left
다음과 같은 출력이 만들어집니다
4 distinct words: [left, came, saw, i]
코드는 항상 구현 타입이 아닌 인터페이스 타입(Set)으로 컬렉션을 참조합니다. 이는 생성자를 변경하는 것만으로 구현을 변경할 수 있는 유연성을 제공하므로 강력하게 권장되는 프로그래밍 방법입니다. 컬렉션을 저장하는 데 사용되는 변수나 컬렉션을 전달하는 데 사용되는 파라미터 중 하나가 인터페이스 타입이 아닌 컬렉션의 구현 타입으로 선언된 경우 구현 타입을 변경하려면 이러한 변수와 파라미터를 모두 변경해야 합니다.
게다가 결과 프로그램이 작동할 것이라는 보장도 없습니다. 프로그램이 원래 구현 타입에는 있지만 새 구현 타입에는 없는 비표준 작업을 사용하는 경우 프로그램은 실패합니다. 인터페이스로만 컬렉션을 참조하면 비표준 작업을 사용할 수 없습니다.
앞의 예제에서 Set의 구현 타입은 HashSet으로, Set 내 엘리먼트의 순서에 대해 아무런 보장을 하지 않습니다. 프로그램이 단어 목록을 알파벳 순서로 출력하도록 하려면 Set의 구현 타입을 HashSet에서 TreeSet으로 변경하면 됩니다. 이 간단한 한 라인의 변경으로 인해 이전 예제의 커맨드라인은 다음과 같은 출력을 생성합니다.
java FindDups i came i saw i left
4 distinct words: [came, i, left, saw]
Set Interface Bulk Operations
Bulk operations는 특히 Set에 잘 맞습니다. 적용될 때, 이들은 표준 집합 대수 연산을 수행합니다. s1과 s2가 set라고 가정해 봅시다. 다음은 bulk operations가 수행하는 작업입니다:
- s1.containsAll(s2) — s2가 s1의 부분 집합(subset)이면 true를 리턴합니다(집합 s1이 s2의 모든 엘리먼트들을 포함하고 있으면 s2는 s1의 부분 집합입니다)
- s1.addAll(s2) — s1을 s1과 s2의 합집합(union)으로 변환합니다(두 집합의 합집합은 두 집합 중 어느 한쪽에 포함된 모든 엘리먼트들을 포함하는 집합입니다)
- s1.retainAll(s2) — s1을 s1과 s2의 교집합(intersection)으로 변환합니다(두 집합의 교집합은 두 집합 모두에 공통으로 포함된 엘리먼트들만을 포함하는 집합입니다)
- s1.removeAll(s2) — s1을 s1과 s2의 (비대칭:asymetric) 차집합(difference)으로 변환합니다(예를 들어, s1에서 s2를 뺀 차집합은 s1에 포함되어 있지만, s2에는 포함되지 않은 모든 엘리먼트들을 포함하는 집합입니다)
두 집합의 합집합, 교집합, 또는 차집합을 비파괴적으로(어느 집합도 수정하지 않고) 계산하려면, 호출자는 적절한 bulk operation을 호출하기 전에 하나의 set를 복사해야 합니다. 다음은 그 결과 관용 코드들입니다.
Set<Type> union = new HashSet<Type>(s1);
union.addAll(s2);
Set<Type> intersection = new HashSet<Type>(s1);
intersection.retainAll(s2);
Set<Type> difference = new HashSet<Type>(s1);
difference.removeAll(s2);
앞서 언급한 관용 코드에서 결과 Set의 구현 타입은 HashSet으로, 이는 이미 언급했듯이 Java 플랫폼에서 가장 범용적인 Set 구현입니다. 그러나 다른 범용 Set 구현을 사용할 수도 있습니다.
이제 FindDups 프로그램을 다시 살펴봅시다. 아규먼트 리스트에서 한 번만 등장하는 단어와 한 번 이상 등장하는 단어를 알고 싶지만, 중복된 단어가 반복해서 출력되지 않기를 원한다고 가정해 봅시다. 이를 위해 두 개의 집합을 생성할 수 있습니다 — 하나는 아규먼트 리스트의 모든 단어를 포함하는 집합이고, 다른 하나는 중복된 단어만 포함하는 집합입니다. 한 번만 등장하는 단어는 이 두 집합의 차집합으로, 이를 계산하는 방법은 이미 알고 있습니다. 다음은 결과 프로그램의 모습입니다:
import java.util.*;
public class FindDups2 {
public static void main(String[] args) {
Set<String> uniques = new HashSet<String>();
Set<String> dups = new HashSet<String>();
for (String a : args)
if (!uniques.add(a))
dups.add(a);
// Destructive set-difference
uniques.removeAll(dups);
System.out.println("Unique words: " + uniques);
System.out.println("Duplicate words: " + dups);
}
}
이전에 사용한 것과 동일한 아규먼트 리스트를 사용하여 실행하면(왔다 갔다 봤다) 프로그램은 다음과 같은 출력을 생성합니다.
Unique words: [left, saw, came]
Duplicate words: [i]
덜 일반적인 집합 대수 연산 중 하나는 대칭 차집합입니다 — 이는 두 지정된 집합 중 어느 한쪽에는 포함되지만 양쪽 모두에는 포함되지 않는 요소들의 집합입니다. 다음 코드는 두 집합의 대칭 차집합을 비파괴적으로 계산합니다.
Set<Type> symmetricDiff = new HashSet<Type>(s1);
symmetricDiff.addAll(s2);
Set<Type> tmp = new HashSet<Type>(s1);
tmp.retainAll(s2);
symmetricDiff.removeAll(tmp);
위 조각 샘플 코드를 프로그램으로 구현한 코드는 다음과 같습니다.
import java.util.HashSet;
import java.util.Set;
public class SymmetricDifference {
public static void main(String[] args) {
Set<String> s1 = new HashSet<>();
s1.add("apple");
s1.add("banana");
s1.add("cherry");
Set<String> s2 = new HashSet<>();
s2.add("banana");
s2.add("date");
s2.add("fig");
// 대칭 차집합을 계산
Set<String> symmetricDiff = new HashSet<>(s1);
symmetricDiff.addAll(s2);
Set<String> tmp = new HashSet<>(s1);
tmp.retainAll(s2);
symmetricDiff.removeAll(tmp);
// 결과 출력
System.out.println("대칭 차집합: " + symmetricDiff);
}
}
위 코드에서 symmetricDiff는 두 집합 s1과 s2의 대칭 차집합을 저장합니다. 먼저 symmetricDiff에 s1과 s2의 모든 요소를 추가한 후, tmp를 사용하여 s1과 s2의 교집합을 계산하고, 이를 symmetricDiff에서 제거하여 대칭 차집합을 얻습니다.
Set Interface Array Operations
배열 연산은 다른 컬렉션에 대해 수행하는 것 외에 Set에 대해 특별한 연산을 수행하지 않습니다. 이러한 연산은 컬렉션 인터페이스 섹션에 설명되어 있습니다.
The List Interface
List는 순서가 있는 Collection(때때로 시퀀스라고도 함)입니다. List는 중복 요소를 포함할 수 있습니다. Collection에서 상속된 연산들 외에도 List 인터페이스에는 다음들을 위한 연산들이 포함됩니다:
- Positional Access — 리스트에서 숫자 위치[인덱스]를 기반으로 엘리먼트를 조작합니다. 여기에는 get, set, add, addAll, remove와 같은 메서드가 포함됩니다.
- Search — 리스트에서 지정된 객체를 검색하고 해당 객체의 인덱스를 리턴합니다. 검색 메소드에서는 indexOf와 lastIndexOf가 포함됩니다.
- Iteration — 리스트의 순차적인 특성을 활용하기 위해 Iterator의 의미[semantics]를 확장합니다. listIterator 메서드가 이러한 동작을 제공합니다.
- Range-view — sublist 메서드는 리스트에서 임의의 범위 작업을 수행합니다.
Java 플랫폼에는 두 가지 범용 List 구현이 포함되어 있습니다. ArrayList는 일반적으로 더 나은 성능을 제공하며, LinkedList는 특정 상황에서 더 나은 성능을 제공합니다.
Collection Operations
Collection에서 상속된 연산은 이미 익숙하다는 가정 하에 예상되는 작업을 수행합니다. 만약 Collection에서 익숙하지 않다면, 지금 The Collection Interface 섹션을 읽어보는 것이 좋습니다. remove 연산은 항상 지정된 엘리먼트의 첫 번째 발생을 리스트에서 제거합니다. add와 addAll 연산은 항상 새 엘리먼트를 리스트의 끝에 추가합니다. 따라서, 다음 관용 코드는 한 리스트를 다른 리스트에 연결합니다.
list1.addAll(list2);
다음은 이 관용 코드의 비파괴적 형태로, 첫 번째 리스트에 두 번째 리스트가 추가된 세 번째 리스트를 생성합니다.
List<Type> list3 = new ArrayList<Type>(list1);
list3.addAll(list2);
이 관용 코드의 비파괴적 형태는 ArrayList의 standard conversion 생성자를 활용한다는 점에 유의하십시오.
다음은 몇몇 이름들을 List로 모으는 예제입니다 (JDK 8 및 이후 버전):
List<String> list = people.stream()
.map(Person::getName)
.collect(Collectors.toList());
Set 인터페이스와 마찬가지로, List는 equals와 hashCode 메서드의 요구 사항을 강화하여 두 List 객체를 구현 클래스에 상관없이 논리적으로 비교할 수 있게 합니다. 두 List 객체는 동일한 순서로 동일한 요소를 포함하고 있으면 같습니다.
다음은 List 인터페이스에서 equals와 hashCode 메서드가 강화된 요구 사항을 충족하는 샘플 코드입니다. 이 예제에서는 두 List 객체가 동일한 순서로 동일한 요소를 포함하고 있을 때 논리적으로 동일함을 보여줍니다.
import java.util.ArrayList;
import java.util.List;
public class ListEqualityExample {
public static void main(String[] args) {
// 첫 번째 리스트 생성
List<String> list1 = new ArrayList<>();
list1.add("John");
list1.add("Alice");
list1.add("Bob");
// 두 번째 리스트 생성
List<String> list2 = new ArrayList<>();
list2.add("John");
list2.add("Alice");
list2.add("Bob");
// 세 번째 리스트 생성 (순서가 다름)
List<String> list3 = new ArrayList<>();
list3.add("Alice");
list3.add("John");
list3.add("Bob");
// 네 번째 리스트 생성 (내용이 다름)
List<String> list4 = new ArrayList<>();
list4.add("John");
list4.add("Alice");
list4.add("Eve");
// 두 리스트가 동일한지 비교
System.out.println("list1 equals list2: " + list1.equals(list2)); // true
System.out.println("list1 equals list3: " + list1.equals(list3)); // false
System.out.println("list1 equals list4: " + list1.equals(list4)); // false
// 두 리스트의 hashCode 비교
System.out.println("list1 hashCode equals list2 hashCode: " + (list1.hashCode() == list2.hashCode())); // true
}
}
위 코드에서 list1과 list2는 동일한 순서로 동일한 엘리먼트를 포함하고 있으므로 equals 메서드는 true를 반환하고, hashCode 메서드의 결과도 동일합니다. 반면, list3과 list4는 list1과 엘리먼트의 순서 또는 내용이 다르므로 equals 메서드는 false를 반환합니다.
Positional Access and Search Operations
기본 위치 접근 연산은 get, set, add 및 remove입니다. (set 및 remove 연산은 덮어쓰거나 제거되는 이전 값을 리턴합니다.) 다른 연산(indexOf 및 lastIndexOf)은 리스트에서 지정된 엘리먼트의 첫 번째 또는 마지막 인덱스를 반환합니다.
addAll 연산은 지정된 위치에서 시작하여 지정된 Collection의 모든 엘리먼트들을 삽입합니다. 엘리먼트들은 지정된 Collection의 반복자가 반환하는 순서대로 삽입됩니다. 이 호출은 Collection의 addAll 연산의 위치 접근 유사체입니다.
다음은 List에서 두 인덱스의 값을 교환하는 간단한 메서드입니다.
public static <E> void swap(List<E> a, int i, int j) {
E tmp = a.get(i);
a.set(i, a.get(j));
a.set(j, tmp);
}
물론 큰 차이점이 하나 있습니다. 이것은 다형성 알고리즘입니다: 구현 타입에 상관없이 어떤 List에서도 두 엘리먼트를 교환합니다. 다음은 앞서 설명한 swap 메서드를 사용하는 또 다른 다형성 알고리즘입니다.
public static void shuffle(List<?> list, Random rnd) {
for (int i = list.size(); i > 1; i--)
swap(list, i - 1, rnd.nextInt(i));
}
이 알고리즘은 Java 플랫폼의 Collections 클래스에 포함되어 있으며, 지정된 난수 소스를 사용하여 지정된 리스트를 무작위로 섞습니다. 이 알고리즘은 약간 미묘합니다: 리스트의 하단에서 시작하여 현재 위치에 무작위로 선택된 요소를 반복적으로 교환합니다. 대부분의 단순한 셔플 시도와 달리, 이는 공정합니다(편향되지 않은 난수 소스를 가정할 때 모든 순열이 동일한 확률로 발생) 그리고 빠릅니다(정확히 리스트 크기 - 1 만큼의 교환이 필요). 다음 프로그램은 이 알고리즘을 사용하여 아규먼트 목록의 단어를 무작위 순서로 출력합니다.
import java.util.*;
public class Shuffle {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
for (String a : args)
list.add(a);
Collections.shuffle(list, new Random());
System.out.println(list);
}
}
사실, 이 프로그램은 더 짧고 빠르게 만들 수 있습니다. Arrays 클래스에는 배열을 List로 볼 수 있게 해주는 asList라는 정적 팩토리 메서드가 있습니다. 이 메서드는 배열을 복사하지 않습니다. List에서의 변경은 배열에 반영되고 그 반대도 마찬가지입니다. 결과로 생성된 List는 일반적인 List 구현이 아니며, (선택적인) add 및 remove 연산을 구현하지 않습니다: 배열은 크기를 변경할 수 없습니다. Arrays.asList를 활용하고 기본 난수 소스를 사용하는 라이브러리 버전의 shuffle을 호출하여, 이전 프로그램과 동일한 동작을 하는 다음과 같은 간단한 프로그램을 얻을 수 있습니다.
import java.util.*;
public class Shuffle {
public static void main(String[] args) {
List<String> list = Arrays.asList(args);
Collections.shuffle(list);
System.out.println(list);
}
}
Iterators
예상대로, List의 iterator 연산이 반환하는 Iterator는 리스트의 엘리먼트들을 올바른 순서로 반환합니다. List는 또한 ListIterator라는 더 풍부한 반복자를 제공하는데, 이를 통해 리스트를 양방향으로 순회하고, 반복 중에 리스트를 수정하며, 반복자의 현재 위치를 얻을 수 있습니다.
ListIterator가 Iterator로부터 상속받은 세 가지 메서드(hasNext, next, remove)는 두 인터페이스에서 동일한 기능을 수행합니다. hasPrevious와 previous 연산은 hasNext와 next의 정확한 유사체입니다. 전자는 (암묵적인) 커서 이전의 엘리먼트를 참조하고, 후자는 커서 이후의 엘리먼트를 참조합니다. previous 연산은 커서를 뒤로 이동시키는 반면, next는 앞으로 이동시킵니다.
다음은 리스트를 역방향으로 반복하는 표준 관용 코드입니다.
for (ListIterator<Type> it = list.listIterator(list.size()); it.hasPrevious(); ) {
Type t = it.previous();
...
}
다음은 주어진 관용 코드를 사용한 샘플 코드입니다:
import java.util.List;
import java.util.ListIterator;
import java.util.Arrays;
public class IterateBackwardSample {
public static void main(String[] args) {
List<String> list = Arrays.asList("apple", "banana", "cherry");
for (ListIterator<String> it = list.listIterator(list.size()); it.hasPrevious(); ) {
String t = it.previous();
System.out.println(t);
}
}
}
위 코드에서 for (ListIterator<String> it = list.listIterator(list.size()); it.hasPrevious(); ) 구문을 사용하여 리스트를 역방향으로 반복합니다. it.previous()를 사용하여 이전 엘리먼트를 가져와 System.out.println(t)로 출력합니다. 이 예제는 리스트의 엘리먼트를 역순으로 출력하는 간단한 프로그램입니다.
위 샘플 코드에서 listIterator에 대한 아규먼트(list.size())를 주목하십시오. List 인터페이스에는 listIterator 메서드의 두 가지 형태가 있습니다. 아규먼트가 없는 형태는 리스트의 시작 부분에 위치한 ListIterator를 반환합니다. int 아규먼트를 사용하는 형태는 지정된 인덱스에 위치한 ListIterator를 리턴합니다. 이 인덱스는 next를 처음 호출했을 때 리턴될 엘리먼트를 참조합니다. previous를 처음 호출했을 때는 인덱스가 index-1인 엘리먼트를 리턴합니다. 길이가 n인 리스트에는 0부터 n까지 포함하여 n+1개의 유효한 인덱스 값이 있습니다.
직관적으로 말하자면, 커서는 항상 두 엘리먼트 사이에 있습니다. 하나는 previous를 호출했을 때 리턴될 엘리먼트이고, 다른 하나는 next를 호출했을 때 리턴될 엘리먼트입니다. n+1개의 유효한 인덱스 값은 엘리먼트 사이의 n+1개의 간격에 해당하며, 첫 번째 엘리먼트 이전의 간격부터 마지막 엘리먼트 이후의 간격까지 포함됩니다. 다음 그림은 네 개의 엘리먼트가 포함된 리스트에서 가능한 다섯 가지 커서 위치를 보여줍니다.
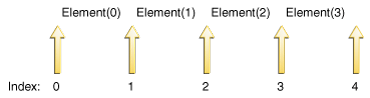
next와 previous 호출은 섞어서 사용할 수 있지만, 약간 주의해야 합니다. 첫 번째 previous 호출은 마지막 next 호출과 동일한 엘리먼트를 반환합니다. 마찬가지로, previous 호출 후에 첫 번째 next 호출은 마지막 previous 호출과 동일한 엘리먼트를 반환합니다.
nextIndex 메서드가 다음 next 호출에서 반환될 엘리먼트의 인덱스를 반환하고, previousIndex 메서드가 다음 previous 호출에서 반환될 엘리먼트의 인덱스를 반환하는 것은 놀라운 일이 아닙니다. 이러한 호출은 일반적으로 무언가가 발견된 위치를 보고하거나, ListIterator의 위치를 기록하여 동일한 위치에 있는 다른 ListIterator를 생성하는 데 사용됩니다.
nextIndex가 반환하는 숫자가 항상 previousIndex가 반환하는 숫자보다 하나 더 크다는 것도 놀라운 일이 아닙니다. 이는 두 가지 경계 사례의 동작을 암시합니다:
(1) 커서가 첫 번째 엘리먼트 이전에 있을 때 previousIndex 호출은 -1을 반환하고,
(2) 커서가 마지막 엘리먼트 이후에 있을 때 nextIndex 호출은 list.size()를 반환합니다.
이를 구체적으로 설명하기 위해, 다음은 List.indexOf의 가능한 구현입니다.
public int indexOf(E e) {
for (ListIterator<E> it = listIterator(); it.hasNext(); )
if (e == null ? it.next() == null : e.equals(it.next()))
return it.previousIndex();
// Element not found
return -1;
}
indexOf 메서드가 리스트를 앞으로 순회하면서도 it.previousIndex()를 반환한다는 점에 주목하십시오. 그 이유는 it.nextIndex()가 우리가 곧 검사할 엘리먼트의 인덱스를 리턴할 것이기 때문이며, 우리는 방금 검사한 엘리먼트의 인덱스를 반환하기를 원하기 때문입니다.
다음은 주어진 indexOf 메서드를 사용하는 샘플 코드입니다:
import java.util.ArrayList;
import java.util.List;
import java.util.ListIterator;
public class CustomList<E> extends ArrayList<E> {
public int indexOf(Object e) {
for (ListIterator<E> it = listIterator(); it.hasNext(); ) {
if (e == null ? it.next() == null : e.equals(it.next())) {
return it.previousIndex();
}
}
// Element not found
return -1;
}
public static void main(String[] args) {
CustomList<String> list = new CustomList<>();
list.add("apple");
list.add("banana");
list.add("cherry");
list.add("date");
System.out.println("Index of 'banana': " + list.indexOf("banana")); // 출력: Index of 'banana': 1
System.out.println("Index of 'cherry': " + list.indexOf("cherry")); // 출력: Index of 'cherry': 2
System.out.println("Index of 'fig': " + list.indexOf("fig")); // 출력: Index of 'fig': -1
}
}
위 코드에서 CustomList 클래스는 ArrayList를 상속받고, indexOf 메서드를 오버라이드하여 주어진 엘리먼트의 인덱스를 리턴합니다. main 메서드에서는 몇 가지 테스트 예제를 통해 리스트에서 엘리먼트의 인덱스를 출력합니다.
Iterator 인터페이스는 Collection에서 next에 의해 반환된 마지막 엘리먼트를 제거하는 remove 연산을 제공합니다. ListIterator의 경우, 이 연산은 next 또는 previous에 의해 반환된 마지막 엘리먼트를 제거합니다. ListIterator 인터페이스는 리스트를 수정하기 위한 두 가지 추가 연산 — set과 add를 제공합니다. set 메서드는 next 또는 previous에 의해 반환된 마지막 엘리먼트를 지정된 엘리먼트로 덮어씁니다. 다음 다형성 알고리즘은 set을 사용하여 한 지정된 값을 다른 값으로 교체하는 모든 발생을 대체합니다.
public static <E> void replace(List<E> list, E val, E newVal) {
for (ListIterator<E> it = list.listIterator(); it.hasNext(); )
if (val == null ? it.next() == null : val.equals(it.next()))
it.set(newVal);
}
이 예제에서 유일하게 까다로운 부분은 val과 it.next 간의 동등성 테스트입니다. NullPointerException을 방지하기 위해 val 값이 null인 경우를 특별히 처리해야 합니다.
다음은 주어진 replace 메서드를 사용하는 샘플 코드입니다:
import java.util.ArrayList;
import java.util.List;
import java.util.ListIterator;
public class ReplaceExample {
public static <E> void replace(List<E> list, E val, E newVal) {
for (ListIterator<E> it = list.listIterator(); it.hasNext(); ) {
if (val == null ? it.next() == null : val.equals(it.next())) {
it.set(newVal);
}
}
}
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("apple");
list.add("banana");
list.add("cherry");
list.add("banana");
list.add("date");
System.out.println("Before replace: " + list);
// "banana"를 "kiwi"로 교체
replace(list, "banana", "kiwi");
System.out.println("After replace: " + list);
// null 값을 테스트하기 위해 null 값을 추가
list.add(null);
System.out.println("Before replace null: " + list);
// null을 "grape"로 교체
replace(list, null, "grape");
System.out.println("After replace null: " + list);
}
}
위 코드에서 main 메서드는 replace 메서드를 사용하여 리스트의 특정 값을 다른 값으로 교체합니다. 예제에서는 banana를 kiwi로, null 값을 grape로 교체하는 작업을 수행합니다. replace 메서드는 ListIterator를 사용하여 리스트를 순회하고, 지정된 값을 찾으면 새로운 값으로 설정합니다.
add 메서드는 새로운 엘리먼트를 현재 커서 위치 바로 앞에 리스트에 삽입합니다. 이 메서드는 지정된 값의 모든 발생을 지정된 리스트에 포함된 값들의 시퀀스로 대체하는 다음 다형성 알고리즘에서 설명됩니다.
public static <E>
void replace(List<E> list, E val, List<? extends E> newVals) {
for (ListIterator<E> it = list.listIterator(); it.hasNext(); ){
if (val == null ? it.next() == null : val.equals(it.next())) {
it.remove();
for (E e : newVals)
it.add(e);
}
}
}
다음은 위 replace 메서드를 사용하는 샘플 코드입니다:
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.ListIterator;
public class ReplaceSequenceExample {
public static <E> void replace(List<E> list, E val, List<? extends E> newVals) {
for (ListIterator<E> it = list.listIterator(); it.hasNext(); ) {
if (val == null ? it.next() == null : val.equals(it.next())) {
it.remove();
for (E e : newVals)
it.add(e);
}
}
}
public static void main(String[] args) {
List<String> list = new ArrayList<>(Arrays.asList("apple", "banana", "cherry", "banana", "date"));
System.out.println("Before replace: " + list);
// "banana"를 {"kiwi", "lime"} 시퀀스로 교체
List<String> newVals = Arrays.asList("kiwi", "lime");
replace(list, "banana", newVals);
System.out.println("After replace: " + list);
// null 값을 테스트하기 위해 null 값을 추가
list.add(null);
System.out.println("Before replace null: " + list);
// null을 {"grape", "melon"} 시퀀스로 교체
List<String> nullNewVals = Arrays.asList("grape", "melon");
replace(list, null, nullNewVals);
System.out.println("After replace null: " + list);
}
}
위 코드에서 main 메서드는 replace 메서드를 사용하여 리스트의 특정 값을 다른 값들의 시퀀스로 교체합니다. 예제에서는 "banana"를 {"kiwi", "lime"} 시퀀스로, null 값을 {"grape", "melon"} 시퀀스로 교체하는 작업을 수행합니다. replace 메서드는 ListIterator를 사용하여 리스트를 순회하고, 지정된 값을 찾으면 이를 제거하고 새로운 값들의 시퀀스를 추가합니다.
Range-View Operation
Range-View 연산인 subList(int fromIndex, int toIndex)는 fromIndex(포함)에서 toIndex(제외)까지의 인덱스 범위를 가지는 리스트의 부분에 대한 리스트 뷰를 반환합니다. 이 반개방 범위(half-open range)는 일반적인 for 루프를 반영합니다.
위에서 말하는 "뷰(view)"란 실제 리스트의 부분 집합에 대한 참조를 의미합니다. 즉, subList 메서드가 반환하는 리스트는 원래 리스트의 요소들을 직접 참조하는 뷰이며, 이 뷰를 통해 요소를 변경하면 원래 리스트에도 영향을 미칩니다. 반대로, 원래 리스트를 수정하면 뷰에도 그 변경이 반영됩니다. 뷰는 원래 리스트의 요소를 복사하지 않고, 요소에 대한 직접 접근을 제공합니다.
for (int i = fromIndex; i < toIndex; i++) {
...
}위에서 말한 "반개방 범위(half-open range)"란 범위의 시작 인덱스는 포함되지만 끝 인덱스는 포함되지 않는 범위를 의미합니다. 예를 들어, subList(int fromIndex, int toIndex)에서 fromIndex는 포함되지만 toIndex는 포함되지 않습니다. 이는 일반적인 for 루프의 동작과 유사합니다. 예를 들어, for (int i = fromIndex; i < toIndex; i++)와 같은 루프에서 i가 fromIndex부터 시작하여 toIndex 이전까지 반복되는 것과 같습니다.
뷰라는 용어가 시사하듯, subList 메서드가 리턴한 List는 subList가 호출된 List에 의해 지원되므로, 리턴된 List의 변경은 원래 List에 반영됩니다.
이 메서드는 명시적인 범위 연산(배열에 일반적으로 존재하는 종류)의 필요성을 제거합니다.
※ 다음은 명시적인 범위 연산을 사용하여 배열의 특정 범위를 제거하는 샘플 코드입니다. 이 예제에서는 배열을 사용하여 특정 범위의 엘리먼트를 제거하고 새로운 배열을 생성합니다.
import java.util.Arrays;
public class ArrayRangeRemoval {
public static void main(String[] args) {
// 원래 배열
int[] array = {1, 2, 3, 4, 5, 6, 7, 8, 9};
// 제거할 범위의 시작 인덱스와 끝 인덱스 (반개방 범위)
int fromIndex = 2;
int toIndex = 5;
// 새로운 배열의 크기
int newSize = array.length - (toIndex - fromIndex);
// 새로운 배열 생성
int[] newArray = new int[newSize];
// 원래 배열의 요소를 새로운 배열로 복사
int index = 0;
for (int i = 0; i < array.length; i++) {
if (i < fromIndex || i >= toIndex) {
newArray[index++] = array[i];
}
}
// 결과 출력
System.out.println("원래 배열: " + Arrays.toString(array));
System.out.println("범위 제거 후 배열: " + Arrays.toString(newArray));
}
}
이 예제에서는 배열 array에서 인덱스 2부터 5까지의 엘리먼트를 제거하고, 새로운 배열 newArray를 생성하여 제거된 엘리먼트를 제외한 나머지 요소를 복사합니다. 결과적으로 새로운 배열에는 원래 배열에서 지정된 범위의 엘리먼트가 제거된 값들이 포함됩니다.
List를 기대하는 모든 연산은 전체 List 대신 subList 뷰를 전달함으로써 범위 연산으로 사용할 수 있습니다. 예를 들어, 다음 관용 코드는 List에서 엘리먼트의 범위를 제거합니다.
list.subList(fromIndex, toIndex).clear();
유사한 관용 코드를 구성하여 범위 내에서 엘리먼트를 검색할 수 있습니다.
int i = list.subList(fromIndex, toIndex).indexOf(o);
int j = list.subList(fromIndex, toIndex).lastIndexOf(o);
앞서 언급한 관용 코드는 지원하는 List(list)의 인덱스가 아닌 subList에서 찾은 엘리먼트의 인덱스를 반환한다는 점에 유의하십시오.
다음은 주어진 관용 코드를 사용하는 샘플 코드입니다:
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class SubListExample {
public static void main(String[] args) {
// 원본 리스트 생성
List<String> list = new ArrayList<>(Arrays.asList("apple", "banana", "cherry", "date", "elderberry", "fig", "grape"));
int fromIndex = 2;
int toIndex = 5;
// subList를 사용하여 범위의 요소를 제거
list.subList(fromIndex, toIndex).clear();
System.out.println("After clear: " + list);
// 리스트를 다시 설정
list = new ArrayList<>(Arrays.asList("apple", "banana", "cherry", "date", "elderberry", "fig", "grape"));
// subList를 사용하여 범위 내 요소의 인덱스를 찾기
int i = list.subList(fromIndex, toIndex).indexOf("date");
System.out.println("Index of 'date' in subList: " + i); // subList 내에서의 인덱스
// subList를 사용하여 범위 내 요소의 마지막 인덱스를 찾기
int j = list.subList(fromIndex, toIndex).lastIndexOf("date");
System.out.println("Last index of 'date' in subList: " + j); // subList 내에서의 마지막 인덱스
}
}
이 코드에서:
1. list.subList(fromIndex, toIndex).clear();는 리스트에서 지정된 범위의 엘리먼트들을 제거합니다.
2. list.subList(fromIndex, toIndex).indexOf("date");는 지정된 범위 내에서 "date" 엘리먼트의 인덱스를 찾습니다.
3. list.subList(fromIndex, toIndex).lastIndexOf("date");는 지정된 범위 내에서 "date" 엘리먼트의 마지막 인덱스를 찾습니다.
출력 결과는 다음과 같습니다:
After clear: [apple, banana, fig, grape]
Index of 'date' in subList: 1
Last index of 'date' in subList: 1
이 예제에서는 "date" 엘리먼트가 제거된 후 다시 리스트를 초기화하여 "date" 엘리먼트를 검색하는 작업을 수행합니다.
replace와 shuffle 예제와 같이 List에서 작동하는 모든 다형성 알고리즘은 subList에 의해 리턴된 List와 함께 작동합니다.
다음은 덱(deck)에서 핸드(hand)를 처리하기 위해 subList를 사용하여 구현하는 다형성 알고리즘입니다. 즉, 지정된 List("데크")의 끝에서 가져온 지정된 수의 엘리먼트를 포함하는 새 List("핸드")을 반환합니다. 핸드에 리턴된 엘리먼트는 덱에서 제거됩니다.
덱(deck)은 카드 게임에서 사용하는 카드 더미를 의미합니다. 핸드(hand)는 플레이어가 카드 더미에서 나누어 받은 카드들을 의미합니다. 따라서 덱은 게임을 시작하기 전에 섞여 있는 전체 카드 묶음이고, 핸드는 그 덱에서 플레이어가 뽑아 가진 카드들의 집합입니다.
public static <E> List<E> dealHand(List<E> deck, int n) {
int deckSize = deck.size();
List<E> handView = deck.subList(deckSize - n, deckSize);
List<E> hand = new ArrayList<E>(handView);
handView.clear();
return hand;
}
이 알고리즘이 덱의 끝에서 핸드를 제거한다는 점에 유의하십시오. ArrayList와 같은 일반적인 List 구현의 경우, 리스트의 시작 부분에서 엘리먼트를 제거하는 것보다 끝 부분에서 엘리먼트를 제거하는 성능이 훨씬 더 좋습니다.
다음은 dealHand 메서드를 Collections.shuffle과 결합하여 일반적인 52장의 카드 덱에서 핸드를 생성하는 프로그램입니다. 이 프로그램은 두 개의 커맨드라인 아규먼트를 받습니다: (1) 나눠줄 핸드의 수와 (2) 각 핸드에 포함될 카드 수입니다.
import java.util.*;
public class Deal {
public static void main(String[] args) {
if (args.length < 2) {
System.out.println("Usage: Deal hands cards");
return;
}
int numHands = Integer.parseInt(args[0]);
int cardsPerHand = Integer.parseInt(args[1]);
// Make a normal 52-card deck.
String[] suit = new String[] {
"spades", "hearts",
"diamonds", "clubs"
};
String[] rank = new String[] {
"ace", "2", "3", "4",
"5", "6", "7", "8", "9", "10",
"jack", "queen", "king"
};
List<String> deck = new ArrayList<String>();
for (int i = 0; i < suit.length; i++)
for (int j = 0; j < rank.length; j++)
deck.add(rank[j] + " of " + suit[i]);
// Shuffle the deck.
Collections.shuffle(deck);
if (numHands * cardsPerHand > deck.size()) {
System.out.println("Not enough cards.");
return;
}
for (int i = 0; i < numHands; i++)
System.out.println(dealHand(deck, cardsPerHand));
}
public static <E> List<E> dealHand(List<E> deck, int n) {
int deckSize = deck.size();
List<E> handView = deck.subList(deckSize - n, deckSize);
List<E> hand = new ArrayList<E>(handView);
handView.clear();
return hand;
}
}
프로그램을 실행하면 다음과 같은 출력이 생성됩니다.
% java Deal 4 5
[8 of hearts, jack of spades, 3 of spades, 4 of spades,
king of diamonds]
[4 of diamonds, ace of clubs, 6 of clubs, jack of hearts,
queen of hearts]
[7 of spades, 5 of spades, 2 of diamonds, queen of diamonds,
9 of clubs]
[8 of spades, 6 of diamonds, ace of spades, 3 of hearts,
ace of hearts]
subList 연산은 매우 강력하지만, 사용할 때는 주의가 필요합니다. 리턴된 List를 통해서가 아닌 다른 방식으로 지원하는 List에 엘리먼트를 추가하거나 제거하면, subList에 의해 리턴된 List의 semantics이 정의되지 않습니다. 따라서 subList에 의해 리턴된 List는 지원하는 List에 대한 하나의 범위 연산 또는 일련의 범위 연산을 수행하기 위한 일시적인 객체로만 사용하는 것이 좋습니다. subList 인스턴스를 오래 사용할수록 지원하는 List를 직접 수정하거나 다른 subList 객체를 통해 수정함으로써 이를 손상시킬 가능성이 커집니다. subList의 subList를 수정하고 원래 subList를 계속 사용하는 것은 합법이지만(동시에 사용하는 것은 제외) 주의가 필요합니다.
다음은 위 설명에 부합하는 샘플 코드입니다. 이 코드는 subList를 일시적으로 사용하여 범위 연산을 수행하고, 지원하는 리스트를 직접 수정하는 경우 subList의 semantics이 정의되지 않음을 보여줍니다.
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class SubListExample {
public static void main(String[] args) {
// 원본 리스트 생성
List<String> list = new ArrayList<>(Arrays.asList("apple", "banana", "cherry", "date", "elderberry", "fig", "grape"));
// subList를 일시적으로 사용하여 범위 연산 수행
List<String> subList = list.subList(2, 5);
System.out.println("Original subList: " + subList);
// subList를 통해 범위 내 요소 수정
subList.set(0, "kiwi");
System.out.println("Modified subList: " + subList);
System.out.println("Original list after subList modification: " + list);
// 지원하는 리스트를 직접 수정하여 subList의 의미가 정의되지 않도록 함
list.add(0, "melon");
System.out.println("Original list after direct modification: " + list);
try {
System.out.println("SubList after original list modification: " + subList);
} catch (Exception e) {
System.out.println("Exception occurred: " + e);
}
// subList의 subList를 수정하고 원래 subList를 계속 사용
List<String> nestedSubList = subList.subList(1, 2);
nestedSubList.set(0, "orange");
System.out.println("Nested subList: " + nestedSubList);
System.out.println("Original subList after nested subList modification: " + subList);
}
}
이 코드는 다음을 보여줍니다:
1. subList를 통해 원본 리스트의 일부를 수정하는 것.
2. 원본 리스트를 직접 수정하면 subList의 의미가 정의되지 않음.
3. subList의 subList를 수정하고 원래 subList를 계속 사용하는 것.
결과 출력은 다음과 같습니다:
Original subList: [cherry, date, elderberry]
Modified subList: [kiwi, date, elderberry]
Original list after subList modification: [apple, banana, kiwi, date, elderberry, fig, grape]
Original list after direct modification: [melon, apple, banana, kiwi, date, elderberry, fig, grape]
Exception occurred: java.util.ConcurrentModificationException
Nested subList: [orange]
Original subList after nested subList modification: [kiwi, orange, elderberry]
위 코드에서 직접 원본 리스트를 수정한 후 subList에 접근하려고 하면 ConcurrentModificationException이 발생할 수 있습니다. 이는 subList의 semantics이 정의되지 않음을 나타냅니다.
List Algorithms
대부분의 다형성 알고리즘은 Collections 클래스에서 List에 특화되어 적용됩니다. 이러한 알고리즘들을 모두 활용할 수 있어 리스트를 매우 쉽게 조작할 수 있습니다. 다음은 이러한 알고리즘들의 요약으로, 자세한 설명은 Algorithms 섹션에서 확인할 수 있습니다.
- sort — sorts a List using a merge sort algorithm, which provides a fast, stable sort. (A stable sort is one that does not reorder equal elements.)
- shuffle — randomly permutes the elements in a List.
- reverse — reverses the order of the elements in a List.
- rotate — rotates all the elements in a List by a specified distance.
- swap — swaps the elements at specified positions in a List.
- replaceAll — replaces all occurrences of one specified value with another.
- fill — overwrites every element in a List with the specified value.
- copy — copies the source List into the destination List.
- binarySearch — searches for an element in an ordered List using the binary search algorithm.
- indexOfSubList — returns the index of the first sublist of one List that is equal to another.
- lastIndexOfSubList — returns the index of the last sublist of one List that is equal to another.