2025. 3. 16. 13:30ㆍSpring Microservice
💡 클라이언트 사이드 복원력(Client-side Resiliency)이 중요한 이유와 구체적인 시나리오 분석하기
지난 글에서는 클라이언트 측 복원력 패턴의 이론적 개념들을 살펴봤는데요, 이번 포스팅에서는 조금 더 구체적인 예제를 통해 왜 이러한 패턴이 중요한지 함께 살펴보겠습니다. 실제 마이크로서비스 환경에서 흔히 일어날 수 있는 장애 상황을 통해 클라이언트 측 복원력의 필요성을 느껴보시죠. 🔍
📌 왜 클라이언트 사이드 복원력 패턴이 필요할까요?
마이크로서비스 기반 아키텍처를 클라우드 환경에서 운영할 때는 수많은 원격 자원들(다른 마이크로서비스, 데이터베이스 등)과 상호작용하게 됩니다. 만약 하나의 원격 자원이 성능 저하나 장애를 겪게 되면 이 문제가 전체 시스템으로 전파되어 심각한 장애로 이어질 수 있습니다. 이를 방지하기 위해 등장한 것이 바로 클라이언트 사이드 복원력(Client-side Resiliency) 패턴입니다. 🛡️
다음 시나리오를 통해 더 깊이 이해해보겠습니다.
🚨 시나리오: 하나의 문제로 전체 시스템이 무너지는 상황 (No Resiliency)
아래의 그림은 여러 애플리케이션과 마이크로서비스들이 상호작용하는 일반적인 상황을 보여줍니다. 여기서는 클라이언트 사이드 복원력 패턴이 적용되지 않은 상태입니다.
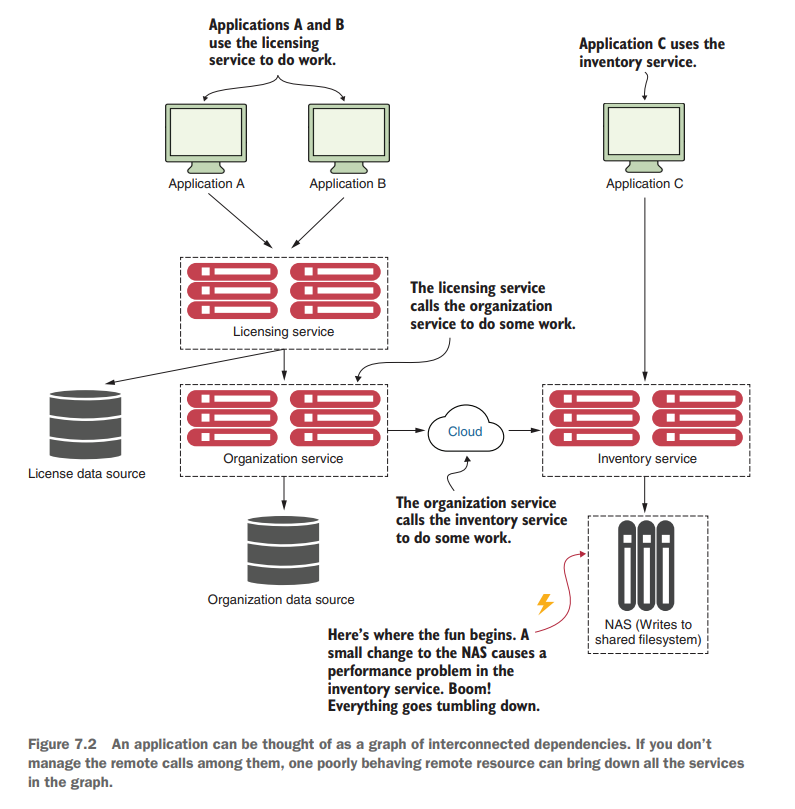
- 애플리케이션 A와 B는 라이센싱 서비스와 직접 통신합니다.
- 라이센싱 서비스는 라이센스 데이터베이스에서 데이터를 가져오고, 다시 조직(Organization) 서비스를 호출하여 추가 작업을 수행합니다.
- 조직 서비스는 별도의 데이터베이스와 외부 클라우드 공급자의 재고(Inventory) 서비스를 호출합니다.
- 이 재고 서비스는 내부적으로 NAS(Network Attached Storage)에 데이터를 기록합니다.
- 애플리케이션 C는 재고 서비스와 직접 통신합니다.
이때 주말에 NAS 관리자가 NAS 구성을 사소하게 변경했습니다. 하지만 이 변경이 월요일 아침에 성능 문제로 나타나기 시작했습니다. 특정 디스크 서브시스템에 대한 읽기 성능이 극도로 느려진 것입니다. 😱
조직 서비스 개발자들은 재고 서비스가 느려질 상황을 고려하지 않고 코드를 작성했습니다. 따라서 재고 서비스 호출이 느려지자 조직 서비스의 쓰레드 풀이 포화 상태에 빠졌고, 데이터베이스 연결 풀이 소진되어 완전히 멈추었습니다.
결과적으로 라이센싱 서비스까지 자원이 부족해지고, 결국 애플리케이션 A, B, C 모두 응답 불능 상태에 빠졌습니다.
이 모든 사태는 원격 자원을 호출하는 지점마다 서킷 브레이커(Circuit breaker)만 적용했더라도 예방할 수 있었습니다.
⚙️ 서킷 브레이커(Circuit breaker)의 실제 적용 예시
서킷 브레이커는 애플리케이션과 원격 서비스 사이에서 중재자 역할을 합니다. 원격 서비스 호출을 별도의 독립적인 쓰레드로 관리하고, 이 호출이 오래 걸리면 빠르게 실패 처리하여 전체 시스템을 보호합니다.
아래 그림을 통해 서킷 브레이커의 세 가지 시나리오를 확인해보겠습니다.
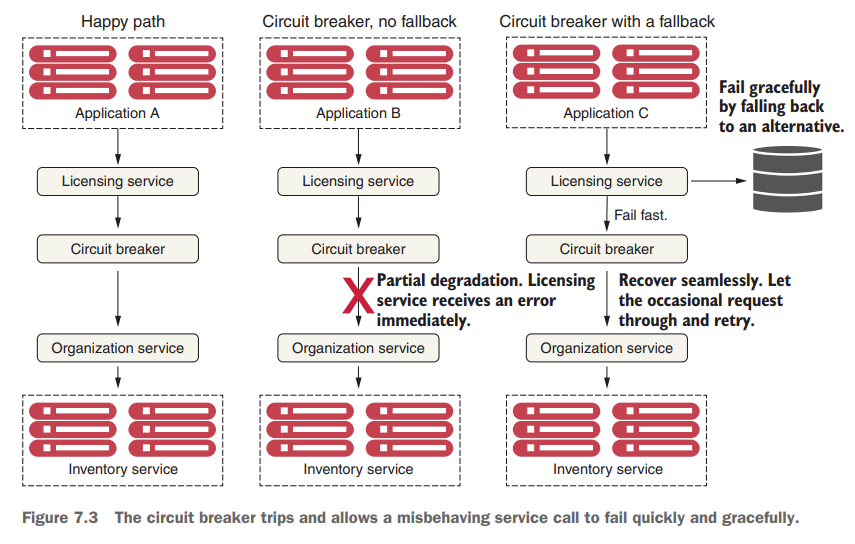
✅ 시나리오 1: 정상 상황 (Happy Path)
- 모든 서비스가 정상적으로 동작합니다.
- 서킷 브레이커는 원격 호출이 타임아웃 되기 전에 성공적으로 완료되는 것을 확인하고 서비스는 정상적으로 처리됩니다.
⚠️ 시나리오 2: 부분적 성능 저하 (Partial Degradation, no fallback)
- 조직 서비스가 느려지면서 서킷 브레이커가 이 호출을 중단합니다.
- 라이센싱 서비스는 즉시 오류를 반환하여 불필요한 리소스 낭비를 방지합니다.
- 만약 같은 오류가 자주 발생하면 서킷 브레이커는 "트립(trip)" 상태가 되어 이후 모든 호출을 즉시 실패처리하여 서비스에 부담을 주지 않습니다.
🛠️ 시나리오 3: 우아한 실패 및 폴백 (Graceful Degradation with fallback)
- 조직 서비스가 장애 상태일 때, 서킷 브레이커는 즉시 문제를 감지하여 빠르게 실패(fail fast) 처리합니다.
- 라이센싱 서비스는 즉시 다른 방법(fallback)을 사용하여 사용자의 요청을 수행할 수 있습니다.
- 서킷 브레이커는 주기적으로 조직 서비스가 정상화되었는지 점검하며, 서비스가 복구되면 다시 정상 호출을 허용합니다. 이 과정에서 사람의 수동 개입 없이도 원활한 복구가 이루어집니다.
🚩 서킷 브레이커를 활용하면 얻는 세 가지 핵심 이점
- 빠르게 실패(Fail fast)
원격 서비스의 문제가 발생했을 때 즉시 실패 처리하여 리소스 소진으로 인한 전체 시스템 장애를 방지합니다. - 우아한 실패(Fail gracefully)
문제가 생겼을 때 즉각적인 대체 경로를 제공하여 사용자의 요구사항을 처리할 수 있습니다. - 원활한 복구(Recover seamlessly)
장애가 발생한 서비스가 정상화되었는지 지속적으로 체크하여 자동으로 서비스가 복구될 수 있도록 지원합니다.
이러한 이점은 대규모 클라우드 환경에서 특히 빛을 발하며, 서비스 장애가 연쇄적으로 퍼지는 것을 방지하고 시스템의 안정성을 유지할 수 있게 합니다.
📚 기술의 변화 (Hystrix → Resilience4j)
이전에는 Java의 대표적인 클라이언트 복원성 라이브러리로 Hystrix를 주로 사용했습니다. 하지만 현재는 Resilience4j가 Hystrix를 대체하여 널리 쓰이고 있으며, Resilience4j는 클라이언트 측 복원력 패턴을 손쉽게 구현하도록 지원합니다.
✏️ 마무리하며
클라이언트 측 복원력 패턴은 마이크로서비스 환경에서 필수적인 구성요소입니다. 단 하나의 원격 서비스 장애가 전체 시스템을 무너뜨리는 치명적 상황을 방지할 수 있는 매우 중요한 패턴들이죠.
마이크로서비스를 설계하고 운영할 때, 반드시 이러한 클라이언트 측 복원력 패턴을 고려하여 견고하고 안정적인 시스템을 구축하시기 바랍니다. 💪🌐
🎯 핵심 키워드:
- Client Resiliency
- Circuit Breaker
- Fallback
- Graceful Degradation
- Resilience4j
🙌 다음 포스팅에서도 더 깊이 있는 내용으로 돌아오겠습니다. 감사합니다!
'Spring Microservice' 카테고리의 다른 글
| Spring Cloud와 Resilience4j를 사용하기 위한 라이센싱 서비스 설정 (0) | 2025.03.16 |
|---|---|
| Implementing Resilience4j (0) | 2025.03.16 |
| 마이크로서비스 안정성을 위한 클라이언트 사이드 Resiliency(복원력) 패턴 (0) | 2025.03.16 |
| Resilience Patterns로 탄탄한 마이크로서비스 구축하기 (0) | 2025.03.16 |
| Feign Client (1) | 2025.03.14 |