2025. 3. 14. 11:52ㆍSpring Microservice
✨ 서비스 디스커버리 아키텍처
마이크로서비스 환경에서 서비스 디스커버리(Service Discovery)는 서비스의 위치를 동적으로 찾고, 부하를 균등하게 분산하며, 장애 발생 시 신속하게 대응하는 핵심 기술입니다. 클라우드 기반 애플리케이션에서는 서비스의 물리적 위치를 수동으로 설정하는 것이 비효율적이므로, 서비스 디스커버리 아키텍처를 활용하여 자동화하는 것이 중요합니다.
이번 글에서는 서비스 디스커버리 아키텍처의 주요 개념과 동작 방식을 살펴보겠습니다. 🚀
🔍 서비스 디스커버리의 4가지 핵심 개념
서비스 디스커버리는 다음 4가지 개념을 중심으로 작동합니다.
1. 🏢 서비스 등록 (Service Registration)
마이크로서비스 인스턴스가 시작되면, 서비스 디스커버리 에이전트에 자신의 IP 주소와 포트 번호를 등록합니다. 이렇게 하면 클라이언트 애플리케이션이 서비스의 위치를 찾을 수 있습니다.
2. 🌍 클라이언트의 서비스 조회 (Client Lookup of Service Address)
클라이언트 애플리케이션은 서비스의 위치를 서비스 디스커버리 에이전트에서 조회합니다. 이를 통해 동적으로 서비스 위치를 결정할 수 있습니다.
3. 🔗 정보 공유 (Information Sharing)
서비스 디스커버리 노드들은 서로 상태 정보를 공유하며, 서비스 인스턴스의 변경 사항을 실시간으로 반영합니다.
4. ⚡ 건강 상태 모니터링 (Health Monitoring)
서비스 인스턴스는 주기적으로 Heartbeat 신호를 서비스 디스커버리 노드에게 전송하여 정상적으로 동작하는지 알립니다. 만약 하트비트가 일정 시간 이상 감지되지 않으면, 해당 서비스 인스턴스를 제거합니다.
🛠️ 주요 구성 요소
🖥️ Client Applications
1️⃣ Client Applications는 웹 브라우저나 최종 사용자(Client-Side Application)가 아니라,
마이크로서비스 아키텍처(MSA)를 구성하는 다른 마이크로서비스 인스턴스를 의미
2️⃣ 서비스의 물리적 IP 주소를 직접 알지 않고, 서비스 디스커버리 에이전트를 통해 동적으로 찾음
🌐 서비스 디스커버리 노드
1️⃣ 동일한 서비스 정보(Registry)를 유지
✅ 서비스 디스커버리 노드들은 각 서비스 인스턴스의 IP 및 포트 정보를 동일하게 복제(Replication)하여 유지합니다.
✅ 서비스 인스턴스가 등록/제거될 때, 모든 디스커버리 노드가 변경 사항을 공유합니다.
✅ Eventually Consistent(최종적 일관성) 모델을 사용하여, 시간이 지나면서 모든 노드의 정보가 동기화됩니다.
2️⃣ 로드 밸런싱 역할 수행
✅ 클라이언트(Client Applications)가 서비스 위치를 요청하면, 서비스 디스커버리 노드는 부하 분산(Load Balancing)하여 서비스 인스턴스의 정보를 반환합니다.
✅ 보통 라운드 로빈(Round Robin) 또는 랜덤(Random) 방식으로 인스턴스를 선택합니다.
✅ 클라이언트가 서비스 요청을 보낼 때, 특정 서비스 인스턴스에 집중되지 않도록 분산 처리함.
📦 서비스 인스턴스(Service Instances)
1️⃣ 실제로 실행중인 마이크로서비스
2️⃣ 서비스 시작 시, IP 주소 및 포트 정보를 서비스 디스커버리 에이전트에 등록
3️⃣ Heartbeat 전송을 통해 정상 상태를 서비스 디스커버리 노드에게 알림
📊 서비스 디스커버리의 동작 방식
📝 서비스 등록 및 조회 프로세스

📌 동작 방식
1️⃣ 🔍 서비스 위치 조회 (Service Lookup)
- 클라이언트 애플리케이션은 서비스 디스커버리 에이전트를 통해 서비스의 위치를 논리적 이름(Logical Name)으로 조회합니다.
- 클라이언트는 서비스의 IP 주소를 직접 알지 않고 서비스 디스커버리 시스템에서 가져옵니다.
2️⃣ 📝 서비스 등록 (Service Registration)
- 새로운 서비스 인스턴스가 시작되면 서비스 디스커버리 에이전트에 자신의 IP 주소를 등록합니다.
- 이 과정이 완료되면 해당 서비스가 다른 애플리케이션에서 접근할 수 있게 됩니다.
3️⃣ 🔄 서비스 디스커버리 노드 간 정보 공유
- 서비스 디스커버리 노드(Service Discovery Nodes)들은 서로 서비스 상태 정보를 공유합니다.
- 이를 통해 하나의 노드에서 발생한 변경 사항이 클러스터 전체에 반영됩니다.
4️⃣ 💓 Health Check & Failure Handling(장애 감지)
- 서비스 인스턴스는 주기적으로 Heartbeat 신호를 보내 자신의 상태를 알립니다.
- 만약 특정 서비스 인스턴스가 응답하지 않으면, 서비스 디스커버리는 해당 인스턴스를 비활성화(제거) 합니다.
🔥 핵심 개념
✅ 서비스 위치 조회를 자동화하여 클라이언트가 직접 IP 주소를 관리할 필요 없음
✅ 서비스 디스커버리 노드 간 동기화를 통해 전체 시스템의 일관성을 유지
✅ 장애 감지 및 자동 복구 메커니즘으로 안정적인 마이크로서비스 운영 가능
이 모델을 활용하면 서비스가 동적으로 추가/삭제될 수 있으며, 시스템 장애 시 자동으로 복구할 수 있습니다. 🚀
🛠️ 클라이언트 사이드 로드 밸런싱(Client-Side Load Balancing)
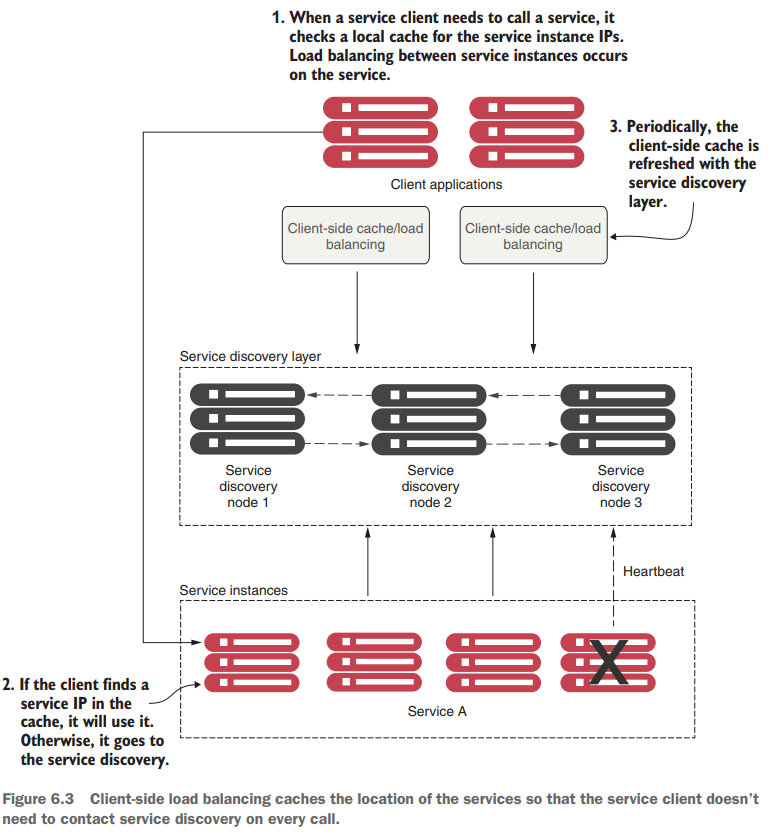
📌 동작 방식
1️⃣ 클라이언트가 서비스 호출 시 로컬 캐시 확인
- 클라이언트 애플리케이션은 먼저 로컬 캐시(Local Cache) 에 저장된 서비스 인스턴스의 IP 정보를 조회합니다.
- 이를 통해 매번 서비스 디스커버리 엔진에 요청하는 부하를 줄입니다.
2️⃣ 캐시에 서비스 IP가 있으면 그대로 사용
- 로컬 캐시에 서비스 IP가 존재하면 해당 IP를 사용하여 직접 요청을 보냅니다.
- 만약 로컬 캐시에 정보가 없다면, 서비스 디스커버리 노드로 이동하여 IP 정보를 조회합니다.
3️⃣ 주기적으로 클라이언트 캐시를 서비스 디스커버리 레이어와 동기화
- 클라이언트는 일정 주기로 서비스 디스커버리 노드(Service Discovery Nodes) 와 통신하여 최신 서비스 목록을 가져옵니다.
- 이렇게 하면 서비스 IP 변경 사항을 반영하면서도 매 요청마다 서비스 디스커버리 노드에 의존하지 않도록 합니다.
🔍 로컬 캐시(Local Cache)란?
✅ 클라이언트(Client Applications) 내부에 저장되는 서비스 인스턴스 목록 캐시
✅ 서비스 디스커버리에서 가져온 서비스 목록을 일정 시간 동안 유지하여 재사용
✅ 매번 서비스 디스커버리 노드를 조회하는 부하를 줄이고, 서비스 호출 속도를 최적화
🛠 로컬 캐시는 클라이언트가 직접 관리
📌 로컬 캐시는 클라이언트 애플리케이션 내부에서 관리되며,
서비스 인스턴스가 추가되거나 제거될 때 주기적으로 갱신(refresh) 됩니다.
✅ 로컬 캐시의 동작 과정
1️⃣ 클라이언트가 서비스 호출 시, 먼저 로컬 캐시 확인
- 클라이언트는 서비스 인스턴스를 요청할 때 서비스 디스커버리를 조회하기 전에 로컬 캐시를 먼저 검색합니다.
- 만약 캐시에 해당 서비스 인스턴스의 IP가 있다면, 서비스 디스커버리를 호출하지 않고 바로 요청을 보냅니다.
2️⃣ 캐시에 정보가 없으면 서비스 디스커버리 노드 조회
- 클라이언트가 로컬 캐시에 없는 서비스를 호출하려는 경우,
서비스 디스커버리 노드(Service Discovery Nodes)에 요청하여 최신 서비스 정보를 가져옵니다.
3️⃣ 클라이언트는 일정 주기로 서비스 디스커버리에서 최신 정보 가져옴
- 서비스 인스턴스가 추가되거나 제거될 때 변경 사항을 반영하기 위해
클라이언트는 주기적으로 서비스 디스커버리에서 최신 서비스 목록을 받아 캐시를 업데이트합니다.
📌 로컬 캐시를 사용하는 이유
✅ 서비스 디스커버리 부하 감소 → 매번 서비스 디스커버리를 조회하는 부담을 줄임
✅ 빠른 응답 속도 → 서비스 위치를 로컬에서 즉시 조회 가능
✅ 장애 시에도 동작 가능 → 서비스 디스커버리가 일시적으로 다운되어도 캐시된 정보로 서비스 호출 가능
✅ 네트워크 트래픽 감소 → 불필요한 서비스 디스커버리 호출을 줄여 성능 최적화
🔥 핵심 개념
✅ 클라이언트 사이드 캐싱을 활용하면, 서비스 디스커버리에 대한 요청 부하를 줄일 수 있음
✅ 클라이언트가 직접 로드 밸런싱을 수행하여 서비스 호출 성능을 최적화할 수 있음
✅ 서비스 장애 감지 후 자동으로 장애 인스턴스를 제거하는 메커니즘을 포함
이 모델을 활용하면 서비스 디스커버리 엔진에 대한 의존도를 줄이면서도 동적으로 부하를 분산할 수 있습니다. 🚀
📚 결론
서비스 디스커버리는 마이크로서비스 환경에서 서비스의 위치를 자동으로 관리하는 필수 기술입니다. 이를 효과적으로 활용하면 서비스 확장성(Scalability)과 장애 대응력(Fault Tolerance)을 높일 수 있습니다.
🚀 핵심 요약
- 서비스 디스커버리는 서비스 등록, 조회, 정보 공유, 건강 상태 모니터링의 4가지 핵심 개념을 기반으로 작동합니다.
- 서비스 디스커버리 노드들은 서로 정보를 공유하며, 장애 감지 및 자동 복구 기능을 수행합니다.
- 클라이언트 사이드 로드 밸런싱을 사용하면 서비스 디스커버리 엔진의 부담을 줄이고, 빠르고 안정적인 서비스 요청이 가능합니다.
다음 글에서는 Spring Cloud와 Netflix Eureka를 활용한 서비스 디스커버리 구현 방법을 다루겠습니다! 🚀
'Spring Microservice' 카테고리의 다른 글
| Spring Boot 마이크로서비스를 Eureka Server에 등록하기 (0) | 2025.03.14 |
|---|---|
| Spring Cloud & Netflix Eureka를 활용한 서비스 디스커버리 구현 (0) | 2025.03.14 |
| 클라우드 환경에서의 서비스 디스커버리 (0) | 2025.03.14 |
| On service discovery (0) | 2025.03.14 |
| Spring Microservices in Action Chapter05 프로젝트 종합 테스트 (0) | 2025.03.13 |