2024. 5. 31. 11:41ㆍHigh Level Programming Language/JDBC Database Access
JDBC API는 특히 관계형 데이터베이스에 저장된 데이터를 포함하여 모든 종류의 테이블 형식 데이터를 액세스할 수 있는 Java API입니다.
JDBC는 다음 세 가지 프로그래밍 활동을 관리하는 Java 애플리케이션을 작성하는 데 도움이 됩니다:
1. data source(예: 데이터베이스)에 연결
2. 데이터베이스에 쿼리와 업데이트 문을 전송
3. 쿼리에 대한 응답으로 데이터베이스에서 받은 결과를 검색하고 처리
다음 간단한 코드 조각은 이 세 가지 단계를 간단하게 예시합니다:
public void connectToAndQueryDatabase(String username, String password) {
Connection con = DriverManager.getConnection(
"jdbc:myDriver:myDatabase",
username,
password);
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery("SELECT a, b, c FROM Table1");
while (rs.next()) {
int x = rs.getInt("a");
String s = rs.getString("b");
float f = rs.getFloat("c");
}
}
이 짧은 코드 조각은 데이터베이스 드라이버에 연결하고 데이터베이스에 로그인하기 위해 DriverManager 객체를 인스턴스화하며, SQL 언어 쿼리를 데이터베이스에 전달하는 Statement 객체를 인스턴스화하고, 쿼리 결과를 검색하는 ResultSet 객체를 인스턴스화한 다음, 간단한 while 루프를 실행하여 그 결과를 검색하고 표시합니다. 매우 간단합니다.
JDBC Product Components
JDBC는 네 개의 컴포넌트들을 가지고 있습니다.:
- The JDBC API — JDBC™ API는 Java™ 프로그래밍 언어에서 관계형 데이터에 대한 프로그래밍 방식 액세스를 제공합니다. JDBC API를 사용하면 애플리케이션은 SQL 문을 실행하고, 결과를 검색하고, 변경 사항을 기본 데이터 소스로 다시 전파할 수 있습니다. JDBC API는 분산된 이기종 환경에서 여러 데이터 소스와 상호 작용할 수도 있습니다.
- JDBC API는 Java 플랫폼의 일부로, Java™ Standard Edition(Java™ SE) 및 Java™ Enterprise Edition(Java™ EE)을 포함합니다. JDBC 4.0 API는 두 개의 패키지로 나누어집니다: java.sql 및 javax.sql. 두 패키지에는 모두 Java SE 및 Java EE 플랫폼이 포함되어 있습니다.
- JDBC Driver Manager — JDBC DriverManager 클래스는 Java 애플리케이션을 JDBC 드라이버에 연결할 수 있는 객체를 정의합니다. DriverManager는 전통적으로 JDBC 아키텍처의 중추였습니다. 이는 매우 작고 간단합니다.
- 표준 확장 패키지( Standard Extension packages) javax.naming 및 javax.sql을 사용하면 Java Naming and Directory Interface™(JNDI) 명명 서비스에 등록된 DataSource 객체를 사용하여 데이터 소스와 연결을 설정할 수 있습니다. 두 연결 메커니즘을 모두 사용할 수 있지만 가능한 경우 DataSource 객체를 사용하는 것이 좋습니다.
- JDBC Test Suite — JDBC 드라이버 테스트 모음은 JDBC 드라이버가 프로그램을 실행할지 여부를 결정하는 데 도움이 됩니다. 이러한 테스트는 포괄적이거나 철저하지는 않지만 JDBC API의 많은 중요한 기능을 실행합니다.
- JDBC-ODBC Bridge — Java Software Bridge는 ODBC 드라이버를 통해 JDBC 액세스를 제공합니다. 이 드라이버를 사용하는 각 클라이언트 머신에 ODBC 바이너리 코드를 로드해야 합니다. 결과적으로 ODBC 드라이버는 클라이언트 설치가 큰 문제가 아닌 기업 네트워크나 3계층 아키텍처에서 Java로 작성된 애플리케이션 서버 코드에 가장 적합합니다.
이 Trail은 이 네 가지 JDBC 구성 요소 중 처음 두 가지를 사용하여 데이터베이스에 연결한 다음 SQL 명령을 사용하여 테스트 관계형 데이터베이스와 통신하는 Java 프로그램을 빌드합니다. 마지막 두 가지 구성 요소는 특수 환경에서 웹 애플리케이션을 테스트하거나 ODBC 인식 DBMS와 통신하는 데 사용됩니다.
JDBC Architecture
JDBC API는 데이터베이스 액세스를 위한 2계층과 3계층 처리 모델을 모두 지원합니다.
Figure 1: Two-tier Architecture for Data Access
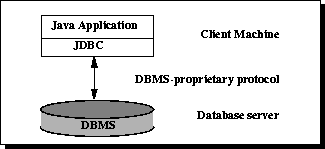
2계층 모델에서는 Java 애플릿이나 애플리케이션이 데이터 소스와 직접 통신합니다. 이를 위해 액세스하는 특정 데이터 소스와 통신할 수 있는 JDBC 드라이버가 필요합니다. 사용자의 명령은 데이터베이스나 다른 데이터 소스로 전달되며, 해당 명령의 결과는 사용자에게 다시 전송됩니다. 데이터 소스는 네트워크를 통해 사용자가 연결된 다른 머신에 위치할 수 있습니다. 이를 클라이언트/서버 구성이라고 하며, 사용자의 머신을 클라이언트로, 데이터 소스를 포함하는 머신을 서버로 지칭합니다. 네트워크는 예를 들어 회사 내부의 직원들을 연결하는 인트라넷일 수도 있고, 인터넷일 수도 있습니다.
3계층 모델에서는 명령이 서비스의 "중간 계층"으로 전송되고, 중간 계층이 해당 명령을 데이터 소스로 전송합니다. 데이터 소스는 명령을 처리하고 결과를 중간 계층으로 보내며, 중간 계층은 이를 사용자에게 전송합니다. MIS 이사들은 중간 계층이 기업 데이터에 대한 액세스 및 업데이트 유형을 제어할 수 있게 해주기 때문에 3계층 모델을 매우 매력적으로 생각합니다. 또 다른 장점은 애플리케이션의 배포를 단순화할 수 있다는 점입니다. 마지막으로, 대부분의 경우 3계층 아키텍처는 성능상의 이점을 제공할 수 있습니다.
Figure 2: Three-tier Architecture for Data Access.
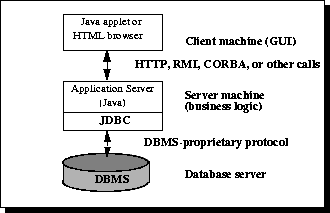
최근까지 중간 계층은 빠른 성능을 제공하는 C나 C++와 같은 언어로 작성되는 경우가 많았습니다. 그러나 Java 바이트코드를 효율적인 기계 전용 코드로 변환하는 최적화 컴파일러와 Enterprise JavaBeans™와 같은 기술의 도입으로 Java 플랫폼은 중간 계층 개발의 표준 플랫폼으로 빠르게 자리 잡고 있습니다. 이는 Java의 견고함, 멀티스레딩 및 보안 기능을 활용할 수 있게 해주는 큰 장점입니다.
기업들이 서버 코드를 작성하는 데 Java 프로그래밍 언어를 점점 더 많이 사용함에 따라 JDBC API는 3계층 아키텍처의 중간 계층에서 점점 더 많이 사용되고 있습니다. JDBC를 서버 기술로 만드는 몇 가지 기능은 연결 풀링, 분산 트랜잭션 및 비연결형 로우셋을 지원하는 것입니다. 또한 JDBC API는 Java 중간 계층에서 데이터 소스에 액세스할 수 있게 해줍니다.
※ 중간 계층 예 : 1Database Connection Utility, Data Access Object, Business Logic, Servlet...
A Relational Database Overview
데이터베이스는 정보를 저장하여 이를 검색할 수 있는 수단입니다. 가장 간단하게 말하자면, 관계형 데이터베이스는 정보를 행과 열로 구성된 테이블 형태로 제공하는 것입니다. 테이블은 같은 유형의 객체(행) 모음이라는 의미에서 관계(relation)라고 합니다. 테이블의 데이터는 공통(common) key나 개념에 따라 관련될 수 있으며, 테이블에서 관련 데이터를 검색할 수 있는 능력이 관계형 데이터베이스라는 용어의 기초가 됩니다. 데이터베이스 관리 시스템(DBMS)은 데이터가 저장, 유지 및 검색되는 방식을 처리합니다. 관계형 데이터베이스의 경우, 관계형 데이터베이스 관리 시스템(RDBMS)이 이러한 작업을 수행합니다. 이 책에서 사용된 DBMS는 RDBMS를 포함하는 일반적인 용어입니다.
Integrity Rules
관계형 테이블은 데이터를 정확하게 유지하고 항상 접근 가능하도록 하기 위해 특정 무결성 규칙을 따릅니다.
첫째, 관계형 테이블의 행은 모두 고유해야 합니다. 행이 중복되면 두 개의 선택 중 어느 것이 올바른 것인지 해결하는 데 문제가 발생할 수 있습니다. 대부분의 DBMS에서는 사용자가 중복 행을 허용하지 않도록 지정할 수 있으며, 그렇게 지정하면 DBMS는 기존 행을 복제하는 행의 추가를 방지합니다.
전통적인 관계형 모델의 두 번째 무결성 규칙은 열 값이 반복 그룹 또는 배열이 되어서는 안 된다는 것입니다.
데이터 무결성의 세 번째 측면은 null 값의 개념과 관련이 있습니다. 데이터베이스는 null 값을 사용하여 데이터가 누락되었음을 나타냄으로써 데이터가 없을 수 있는 상황을 처리합니다. null 값은 공백이나 0과 같지 않습니다. 공백은 다른 공백
과 같으며, 0은 다른 0과 같지만 두 개의 null 값은 같지 않다고 간주됩니다.
※ 관계형 데이터베이스에서 열 값이 반복 그룹 또는 배열이 되어서는 안 된다는 규칙은 데이터를 정규화하여 각 열이 단일 값을 가지도록 보장합니다. 이 규칙을 이해하기 위해 두 가지 예시를 들어보겠습니다.
예시 1: 반복 그룹이 있는 비정규화된 테이블
비정규화된 Students 테이블
위 테이블에서는 각 학생이 여러 과목을 수강하고 있는데, Course1, Course2, Course3와 같이 과목 정보를 여러 열에 반복적으로 저장하고 있습니다. 이 구조는 확장성이 떨어지고, 새로운 과목이 추가되면 테이블 구조를 변경해야 하는 문제가 있습니다.
Student_ID Name Course1 Course2 Course3 1 Alice Math Science History 2 Bob English Math null 3 Charlie Science null null
예시 2: 정규화된 테이블
위 문제를 해결하기 위해 테이블을 정규화하여 각 열이 단일 값을 가지도록 할 수 있습니다.
정규화된 Students 테이블
Courses 테이블
Student_ID Name 1 Alice 2 Bob 3 Charlie
Enrollments 테이블
Course_ID Course_Name 1 Math 2 Science 3 HIstory 4 English
위와 같이 정규화된 구조에서는 Students, Courses, Enrollments 테이블로 나누어 각 테이블이 단일 값을 가지도록 했습니다. 이제 각 학생이 수강하는 과목은 Enrollments 테이블에서 관리됩니다. 이 방식의 장점은 다음과 같습니다:
Student_ID Course_ID 1 1 1 2 1 3 2 4 2 1 3 2
⦁ 확장성: 새로운 과목을 추가하더라도 테이블 구조를 변경할 필요가 없습니다.
⦁ 데이터 무결성: 학생과 과목 간의 관계를 쉽게 관리할 수 있습니다.
⦁ 중복 제거: 데이터 중복을 최소화하여 저장 공간을 효율적으로 사용합니다.이 예시는 관계형 데이터베이스에서 열 값이 반복 그룹 또는 배열이 되어서는 안 된다는 규칙의 중요성을 보여줍니다. 데이터가 정규화됨으로써 구조가 간단해지고, 데이터 무결성과 확장성이 향상됩니다.
테이블의 각 행이 다를 때, 하나 이상의 컬럼을 사용하여 특정 행을 식별할 수 있습니다. 이러한 고유한 컬럼 또는 컬럼 그룹(복합 키)을 기본 키(primary key)라고 합니다. 기본 키의 일부인 열은 null일 수 없습니다. null 값이 되면 해당 기본 키는 더 이상 완전한 식별자가 아니게 됩니다. 이 규칙을 엔터티 무결성(entity integrity)이라고 합니다.
Employees 테이블은 이러한 관계형 데이터베이스 개념 중 일부를 보여줍니다. 이 테이블은 다섯 개의 열과 여섯 개의 행으
로 구성되어 있으며, 각 행은 다른 직원을 나타냅니다.
Employees Table
| Employee_Number | First_name | Last_Name | Date_of_Birth | Car_Number |
| 10001 | Axel | Washington | 28-Aug-43 | 5 |
| 10083 | Arvid | Sharma | 24-Nov-54 | null |
| 10120 | Jonas | Ginsberg | 01-Jan-69 | null |
| 10005 | Florence | Wojokowski | 04-Jul-71 | 12 |
| 10099 | Sean | Washington | 21-Sep-66 | null |
| 10035 | Elizabeth | Yamaguchi | 24-Dec-59 | null |
이 테이블의 기본 키는 일반적으로 직원 번호가 되는데, 각 번호가 다르다는 것이 보장되기 때문입니다. (숫자는 문자열보다 비교하는 데 더 효율적입니다.) 또한 기본 키로 First_Name과 Last_Name의 조합을 사용할 수도 있습니다. 두 개의 조합이 샘플 데이터베이스에서 하나의 행만 식별하기 때문입니다. 성만 사용하는 것은 "Washington" 성을 가진 두 명의 직원이 있기 때문에 작동하지 않습니다. 이 샘플 경우에는 이름이 모두 다르므로 이 열을 기본 키로 사용할 수 있지만, 중복이 발생할 수 있는 열을 사용하는 것은 피하는 것이 좋습니다. Elizabeth Yamaguchi가 이 회사에 취직하게 되면 기본 키가 First_Name인 경우 RDBMS는 그녀의 이름을 추가할 수 없습니다(중복이 허용되지 않도록 지정된 경우). 테이블에 이미 Elizabeth가 있기 때문에 두 번째 Elizabeth를 추가하면 기본 키가 하나의 행을 식별하는 데 쓸모가 없게 됩니다. First_Name과 Last_Name을 사용하는 것이 이 예제에서는 고유한 복합 키이지만, 더 큰 데이터베이스에서는 고유하지 않을 수 있습니다. 또한 Employees 테이블은 직원당 한 대의 자동차만 있을 수 있다고 가정합니다.
SELECT Statements
SQL은 관계형 데이터베이스와 함께 사용하도록 설계된 언어입니다. 모든 RDBMS에서 표준으로 간주되고 사용되는 기본 SQL 명령 세트가 있습니다. 예를 들어, 모든 RDBMS는 SELECT 문을 사용합니다.
SELECT 문(쿼리라고도 함)은 테이블에서 정보를 가져오는 데 사용됩니다. 이 쿼리문은 하나 이상의 열 제목, 선택할 하나 이상의 테이블 및 선택에 대한 몇 가지 기준을 지정합니다. RDBMS는 명시된 요구 사항을 충족하는 열 엔트리들의 행들을 반환합니다. 다음과 같은 SELECT 문은 회사 차량을 소유한 직원의 이름과 성을 가져옵니다.
SELECT First_Name, Last_Name
FROM Employees
WHERE Car_Number IS NOT NULL
결과 집합[ResultSet](Car_Number 열에 null이 없다는 요구 사항을 충족하는 행 집합)이 다음과 같습니다. SELECT 문(첫 번째 줄)이 First_Name과 Last_Name 열을 지정하기 때문에 요구 사항을 충족하는 각 행에 대해 이름과 성이 출력됩니다. FROM 절(두 번째 줄)은 열이 선택될 테이블을 제공합니다.
| FIRST_NAME | LAST_NAME |
| Axel | Washingto |
| Florence | Wojokowski |
다음 코드는 Employees 테이블의 모든 열을 요청하고 아무런 제한 조건(WHERE 절)이 없기 때문에 전체 테이블을 포함하는 결과 집합을 생성합니다. SELECT *는 "모든 열을 선택"이라는 의미입니다.
SELECT *
FROM Employees
WHERE Clauses
SELECT 문에서 WHERE 절은 값을 선택하기 위한 기준을 제공합니다. 예를 들어, 다음 코드 조각에서는 Last_Name 열이 Washington 문자열로 시작하는 행에서만 값이 선택됩니다.
SELECT First_Name, Last_Name
FROM Employees
WHERE Last_Name LIKE 'Washington%'
LIKE 키워드는 문자열을 비교하는 데 사용되며, 와일드카드를 포함한 패턴을 사용할 수 있는 기능을 제공합니다. 예를 들어, 위의 코드 조각에서 Washington 끝에 있는 퍼센트 기호(%)는 Washington 문자열과 그 뒤에 0개 이상의 추가 문자가 포함된 모든 값을 만족시킨다는 것을 의미합니다. 따라서 Washington이나 Washingtonian은 일치하지만, Washing은 일치하지 않습니다. LIKE 절에서 사용되는 또 다른 와일드카드는 밑줄(_)로, 이는 임의의 한 문자를 나타냅니다. 예를 들어,
WHERE Last_Name LIKE 'Ba_man'
은 Barman, Badman, Balman, Bagman, Bamman 등을 일치시킵니다.
아래의 코드 조각은 숫자를 비교하기 위해 등호(=)를 사용하는 WHERE 절을 포함합니다. 이는 차 번호가 12로 지정된 직원의 이름과 성을 선택합니다.
SELECT First_Name, Last_Name
FROM Employees
WHERE Car_Number = 12
다음 코드 조각은 직원 번호가 10005보다 큰 직원의 이름과 성을 선택합니다.
SELECT First_Name, Last_Name
FROM Employees
WHERE Employee_Number > 10005
WHERE 절은 여러 조건과 일부 DBMS에서는 중첩 조건을 사용하여 다소 복잡해질 수 있습니다. 이 개요에서는 복잡한 WHERE 절을 다루지 않지만, 다음 코드 조각은 두 개의 조건이 있는 WHERE 절을 포함합니다. 이 쿼리는 직원 번호가 10100보다 작고 회사 차가 없는 직원의 이름과 성을 선택합니다.
SELECT First_Name, Last_Name
FROM Employees
WHERE Employee_Number < 10100 AND Car_Number IS NULL
특별한 유형의 WHERE 절에는 JOIN이 포함되며, 이는 다음 섹션에서 설명합니다.
Joins
관계형 데이터베이스의 특징 중 하나는 조인(join)이라고 불리는 방법으로 여러 테이블에서 데이터를 가져올 수 있다는 것입니다. 예를 들어, 회사 차를 보유한 직원의 이름을 검색한 후, 각 직원이 어떤 차를 가지고 있는지, 차의 제조사, 모델, 연도 등의 정보를 알고 싶다고 가정해봅시다. 이 정보는 다른 테이블인 Cars에 저장되어 있습니다:
Cars Table
| Car_Number | Make | Model | Year |
| 5 | Honda | Civic DX | 1996 |
| 12 | Toyota | Corolla | 1999 |
두 테이블을 서로 연관시키기 위해서는 두 테이블 모두에 나타나는 하나의 열이 있어야 합니다. 이 열은 한 테이블에서는 기본 키(primary key)이고 다른 테이블에서는 외래 키(foreign key)라고 합니다. 이 경우, 두 테이블에 나타나는 열은 Car_Number이며, 이 Car_Number는 Cars 테이블에서는 기본 키이고 Employees 테이블에서는 외래 키입니다. 만약 1996년형 혼다 시빅이 파손되어 Cars 테이블에서 삭제된다면, 참조 무결성(referential integrity)을 유지하기 위해 Employees 테이블에서도 Car_Number 5를 삭제해야 합니다. 그렇지 않으면, Employees 테이블의 외래 키 열(Car_Number)에는 Cars 테이블에 아무 것도 참조하지 않는 항목이 포함됩니다. 외래 키는 null이거나 참조하는 테이블의 기존 기본 키 값과 같아야 합니다. 이는 null일 수 없는 기본 키와 다릅니다. Employees 테이블의 Car_Number 열에는 여러 개의 null 값이 있는데, 이는 직원이 회사 차를 가지고 있지 않을 수 있기 때문입니다.
다음 코드는 회사 차를 가지고 있는 직원의 이름과 해당 차의 제조사, 모델, 연도를 요청합니다. 요청된 데이터가 두 테이블 모두에 포함되어 있기 때문에 FROM 절에 Employees와 Cars 테이블이 나열되어 있는 것을 주목하세요. 테이블 이름과 점(.)을 열 이름 앞에 사용하여 어느 테이블에 열이 포함되어 있는지를 나타냅니다.
SELECT Employees.First_Name, Employees.Last_Name,
Cars.Make, Cars.Model, Cars.Year
FROM Employees, Cars
WHERE Employees.Car_Number = Cars.Car_Number
이 쿼리는 다음과 유사한 ResultSet을 반환합니다:
| FIRST_NAME | LAST_NAME | LICENSE_PLATE | MILEAGE | YEAR |
| John | Washington | ABC123 | 5000 | 1996 |
| Florence | Wojokowski | DEF123 | 7500 | 1999 |
Common SQL Commands
SQL 명령어는 여러 카테고리로 나눌 수 있으며, 주요한 두 가지는 데이터 조작 언어(DML) 명령어와 데이터 정의 언어(DDL) 명령어입니다. DML 명령어는 데이터를 조회하거나 수정하여 최신 상태로 유지하는 데 사용됩니다. DDL 명령어는 테이블 및 뷰, 인덱스와 같은 다른 데이터베이스 객체를 생성하거나 변경합니다.
더 일반적인 DML 명령어 목록은 다음과 같습니다:
⦁ SELECT — 데이터베이스에서 데이터를 조회하고 표시하는 데 사용됩니다. SELECT 문은 결과 집합에 포함할 열을 지정합니다. 애플리케이션에서 사용되는 SQL 명령어의 대다수는 SELECT 문입니다.
⦁ INSERT — 테이블에 새로운 행을 추가합니다. INSERT는 새로 생성된 테이블에 데이터를 채우거나 이미 존재하는 테이블에 새로운 행을 추가하는 데 사용됩니다.
Employees 테이블에 데이터를 삽입하는 예시
<insert single row 예시>
INSERT INTO Employees (First_Name, Last_Name, Date_Of_Birth, Car_Number)
VALUES ('John', 'Doe', '1985-06-15', 3);
<insert multiple rows 예시>
INSERT INTO Employees (First_Name, Last_Name, Date_Of_Birth, Car_Number)
VALUES
('Jane', 'Smith', '1990-07-22', 4),
('Emily', 'Jones', '1978-12-11', 5),
('Michael', 'Brown', '1983-04-08', NULL);
⦁ DELETE — 테이블에서 지정된 행 또는 행 집합을 제거합니다.
Employees 테이블에 데이터를 삭제하는 예시
<특정 row 삭제: Employee_Number가 3인 직원 삭제>
DELETE FROM Employees
WHERE Employee_ID = 3;
<특정 row 삭제: 성이 Smith 인 모든 직원 삭제>
DELETE FROM Employees
WHERE Last_Name = 'Smith';
<여러 조건을 사용하여 row 삭제: 회사 차를 보유하고 있지 않은 직원 삭제>
DELETE FROM Employees
WHERE Car_Number IS NULL;
<여러 조건을 사용하여 row 삭제: 특정 날짜 이전에 태어난 직원 삭제>
DELETE FROM Employees
WHERE Date_Of_Birth < '1980-01-01';
⦁ UPDATE — 테이블의 열 또는 열 그룹의 기존 값을 변경합니다.
<특정 열을 업데이트>
1. 직원 번화가 3인 직원의 이름 업데이트
UPDATE Employees
SET First_Name = 'Michael', Last_Name = 'Johnson'
WHERE Employee_ID = 3;
2. 성이 'Doe'인 직원들의 회사 차 번호를 10으로 업데이트
UPDATE Employees
SET Car_Number = 10
WHERE Last_Name = 'Doe';
<여러 열을 업데이트>
3. 직원 번호가 2인 직원의 이름과 생년월일 업데이트
UPDATE Employees
SET First_Name = 'Emily', Date_Of_Birth = '1985-05-15'
WHERE Employee_ID = 2;
<조건에 따라 여러 행 업데이트>
4. 생년월일이 1990년 이후인 직원들의 성을 'Young'으로 업데이트
UPDATE Employees
SET Last_Name = 'Young'
WHERE Date_Of_Birth > '1990-01-01';
<계산된 값을 사용하여 업데이트>
5. 회사 차 번호가 null인 직원들의 번호를 1 증가 시키기
UPDATE Employees
SET Car_Number = Car_Number + 1
WHERE Car_Number IS NOT NULL;
더 일반적인 DDL 명령어 목록은 다음과 같습니다:
⦁ CREATE TABLE — 사용자가 제공한 열 이름으로 테이블을 생성합니다. 사용자는 각 열에 대한 데이터 유형도 지정해야 합니다. 데이터 유형은 RDBMS마다 다르므로 사용자는 특정 데이터베이스에서 사용되는 데이터 유형을 설정하기 위해 메타데이터를 사용할 필요가 있습니다. CREATE TABLE은 일반적으로 데이터 조작 명령어보다 덜 자주 사용됩니다. 이는 테이블은 한 번만 생성되지만, 행을 추가하거나 삭제하거나 개별 값을 변경하는 작업은 더 빈번하게 발생하기 때문입니다.
CREATE TABLE Employees (
Employee_ID INT AUTO_INCREMENT PRIMARY KEY,
First_Name VARCHAR(50),
Last_Name VARCHAR(50),
Date_Of_Birth DATE,
Car_Number INT
);
⦁ DROP TABLE — 모든 행을 삭제하고 데이터베이스에서 테이블 정의를 제거합니다. JDBC API 구현은 SQL92, Transitional Level에 따라 DROP TABLE 명령어를 지원해야 합니다. 그러나 DROP TABLE의 CASCADE 및 RESTRICT 옵션 지원은 선택 사항입니다. 또한, 삭제되는 테이블을 참조하는 뷰 또는 무결성 제약 조건이 정의된 경우 DROP TABLE의 동작은 구현에 따라 달라집니다.
DROP TABLE Employees;
또는 여러 테이블 동시에 삭제
DROP TABLE Employees, Cars;
CASCADE 옵션 사용 예시
※ CASCADE 옵션은 데이터베이스에서 DROP TABLE, DELETE 또는 UPDATE 명령어를 사용할 때 관련된 데이터도 함께 자동으로 처리되도록 하는 옵션입니다. MySQL에서는 기본적으로 CASCADE 옵션이 DROP TABLE
명령어에 직접적으로 지원되지 않지만, 외래 키 제약 조건을 사용할 때 DELETE 또는 UPDATE 명령어와 함께 사용될 수 있습니다.
예시: Employees 테이블과 관련된 Projects 테이블이 있다고 가정해보겠습니다.
CREATE TABLE Employees ( Employee_ID INT AUTO_INCREMENT PRIMARY KEY, First_Name VARCHAR(50), Last_Name VARCHAR(50), Date_Of_Birth DATE, Car_Number INT ); CREATE TABLE Projects ( Project_ID INT AUTO_INCREMENT PRIMARY KEY, Project_Name VARCHAR(100), Employee_ID INT, FOREIGN KEY (Employee_ID) REFERENCES Employees(Employee_ID) );
Employees 테이블을 삭제하려면 먼저 Projects 테이블을 삭제해야 합니다.
Employees 및 Projects 테이블 삭제
DROP TABLE Projects; DROP TABLE Employees;
⦁ ALTER TABLE — 테이블에서 열을 추가하거나 제거합니다. 또한 테이블 제약 조건을 추가하거나 삭제하고 열 속성을 변경합니다.
MySQL에서 ALTER TABLE 명령어를 사용하여 테이블의 구조를 변경하는 다양한 예시를 보여드리겠습니다.
예시 1: 테이블에 새로운 열 추가
ALTER TABLE Employees
ADD COLUMN Email VARCHAR(100);
예시 2: 열의 데이터 타입 변경
ALTER TABLE Employees
MODIFY COLUMN Last_Name VARCHAR(100);
예시 3: 열 이름 변경
ALTER TABLE Employees
CHANGE COLUMN Car_Number Vehicle_Number INT;
예시 4: 열 삭제
ALTER TABLE Employees
DROP COLUMN Date_Of_Birth;
예시 5: 테이블에 제약 조건 추가
1. 기본 키 추가
ALTER TABLE Employees ADD PRIMARY KEY (Employee_ID);
2. 외래 키 추가
ALTER TABLE Projects ADD CONSTRAINT fk_employee FOREIGN KEY (Employee_ID) REFERENCES Employees(Employee_ID) ON DELETE CASCADE;
예시 6: INNER JOIN
조인의 주체가 Employees 인 경우,
SELECT e.Employee_ID, e.First_Name, e.Last_Name, e.Date_Of_Birth, e.Car_Number, p.Project_ID, p.Project_Name FROM Employees e JOIN Projects p ON e.Employee_ID = p.Employee_ID;
조인의 주체가 Projects인 경우
SELECT p.Project_ID, p.Project_Name, e.First_Name, e.Last_Name FROM Projects p JOIN Employees e ON p.Employee_ID = e.Employee_ID;
예시 7: LEFT JOIN
조인의 주체가 Employees인 경우
SELECT e.Employee_ID, e.First_Name, e.Last_Name, e.Date_Of_Birth, e.Car_Number, p.Project_ID, p.Project_Name FROM Employees e LEFT JOIN Projects p ON e.Employee_ID = p.Employee_ID;
조인의 주체가 Projects 인 경우
SELECT p.Project_ID, p.Project_Name, p.Employee_ID, e.First_Name, e.Last_Name, e.Date_Of_Birth, e.Car_Number FROM Projects p LEFT JOIN Employees e ON p.Employee_ID = e.Employee_ID;
예시 8: 열의 기본값 설정
ALTER TABLE Employees
ALTER COLUMN Car_Number SET DEFAULT 0;
예시 9: 테이블 이름 변경
ALTER TABLE Employees
RENAME TO Staff;
예시 10: 제약 조건 삭제
1. 외래 키 제약 조건 삭제
ALTER TABLE Projects DROP FOREIGN KEY fk_employee;
2. 기본 키 제약 조건 삭제
ALTER TABLE Employees DROP PRIMARY KEY;
Result Sets and Cursors
쿼리의 조건을 만족하는 행들을 Result Sets이라고 합니다. ResultSet에 반환되는 행의 수는 0, 1 또는 그 이상일 수 있습니다. 사용자는 ResultSet의 데이터를 한 번에 한 행씩 접근할 수 있으며, 커서는 이를 수행하는 수단을 제공합니다. 커서는 ResultSet의 행들을 포함하는 파일 안의 포인터로 생각할 수 있으며, 현재 접근 중인 행을 추적할 수 있습니다. 커서는 사용자가 ResultSet의 각 행을 위에서 아래로 처리할 수 있게 하며, 따라서 반복 처리에 사용할 수 있습니다. 대부분의 DBMS는 ResultSet이 생성될 때 커서를 자동으로 생성합니다.
이전 JDBC API 버전들은 ResultSet의 커서에 새로운 기능을 추가하여 커서가 앞으로와 뒤로 이동할 수 있게 하고, 특정 행으로 또는 다른 행에 상대적인 위치로 이동할 수 있게 했습니다.
ResultSet에서 값을 검색하고 수정하는 방법에 대한 자세한 내용은 [ ResultSet에서 값 검색 및 수정](https://docs.oracle.com/javase/tutorial/jdbc/basics/retrieving.html)을 참조하세요.
Transactions
한 사용자가 데이터베이스의 데이터를 접근하고 있을 때, 다른 사용자도 동시에 같은 데이터를 접근할 수 있습니다. 예를 들어, 첫 번째 사용자가 테이블의 일부 열을 업데이트하는 동안 두 번째 사용자가 같은 테이블의 열을 선택하고 있다면, 두 번째 사용자는 일부는 오래된 데이터이고 일부는 업데이트된 데이터를 얻을 수 있습니다. 이러한 이유로 DBMS는 여러 사용자가 동시에 데이터베이스에 접근할 수 있도록 하면서도 데이터 일관성(data consistency)을 유지하기 위해 트랜잭션을 사용합니다.
트랜잭션은 하나 이상의 SQL 문으로 구성된 논리적 작업 단위입니다. 트랜잭션은 데이터 일관성이나 데이터 동시성에 문제가 있는지 여부에 따라 커밋(commit) 또는 롤백(rollback)으로 끝납니다. 커밋 문은 트랜잭션의 SQL 문에 의한 변경을 영구적으로 적용하며, 롤백 문은 트랜잭션의 SQL 문에 의한 모든 변경을 취소합니다.
락(lock)은 두 트랜잭션이 동시에 동일한 데이터를 조작하는 것을 금지하는 메커니즘입니다. 예를 들어, 테이블 락은 해당 테이블에 커밋되지 않은 트랜잭션이 있을 경우 테이블이 삭제되는 것을 방지합니다. 일부 DBMS에서는 테이블 락이 테이블의 모든 행을 잠그기도 합니다. 행 락은 두 트랜잭션이 동일한 행을 수정하는 것을 방지하거나, 한 트랜잭션이 아직 행을 수정 중일 때 다른 트랜잭션이 해당 행을 선택하는 것을 방지합니다.
트랜잭션 사용에 대한 자세한 내용은 [트랜잭션 사용](https://docs.oracle.com/javase/tutorial/jdbc/basics/transactions.html)을 참조하세요.
Stored Procedures
저장 프로시저는 이름으로 호출할 수 있는 SQL 문 그룹입니다. 즉, 특정 작업을 수행하는 실행 가능한 코드, 작은 프로그램으로, 함수나 메서드를 호출하는 것과 같은 방식으로 호출할 수 있습니다. 전통적으로 저장 프로시저는 DBMS별 프로그래밍 언어로 작성되었습니다. 최신 데이터베이스 제품들은 Java 프로그래밍 언어와 JDBC API를 사용하여 저장 프로시저를 작성할 수 있게 합니다. Java 프로그래밍 언어로 작성된 저장 프로시저는 DBMS 간에 바이트코드로 이식 가능합니다. 저장 프로시저가 작성되면, 이를 지원하는 DBMS는 이를 데이터베이스에 저장하기 때문에 저장 프로시저를 사용하고 재사용할 수 있습니다. 저장 프로시저 작성에 대한 자세한 내용은 [저장 프로시저 사용](https://docs.oracle.com/javase/tutorial/jdbc/basics/storedprocedures.html)을 참조하세요.
Metadata
데이터베이스는 사용자 데이터를 저장할 뿐만 아니라 데이터베이스 자체에 대한 정보도 저장합니다. 대부분의 DBMS는 데이터베이스의 테이블, 각 테이블의 열 이름, 기본 키, 외래 키, 저장 프로시저 등을 나열하는 시스템 테이블 집합을 가지고 있습니다. 각 DBMS는 테이블 레이아웃과 데이터베이스 기능에 대한 정보를 얻기 위한 자체 기능을 가지고 있습니다. JDBC는 드라이버 작성자가 드라이버 및/또는 드라이버가 작성된 DBMS에 대한 정보를 반환하도록 구현해야 하는 DatabaseMetaData 인터페이스를 제공합니다. 예를 들어, 많은 메서드가 드라이버가 특정 기능을 지원하는지 여부를 반환합니다. 이 인터페이스는 사용자와 도구가 메타데이터를 얻기 위한 표준화된 방법을 제공합니다. 일반적으로 도구 및 드라이버를 작성하는 개발자가 메타데이터에 가장 관심을 가질 가능성이 높습니다.
출처: https://docs.oracle.com/javase/tutorial/jdbc/overview/index.html
Lesson: JDBC Introduction (The Java™ Tutorials > JDBC Database Access)
The Java Tutorials have been written for JDK 8. Examples and practices described in this page don't take advantage of improvements introduced in later releases and might use technology no longer available. See Dev.java for updated tutorials taking advantag
docs.oracle.com
'High Level Programming Language > JDBC Database Access' 카테고리의 다른 글
| Setting Up Tables (0) | 2025.04.06 |
|---|---|
| Handling SQLExceptions (0) | 2025.04.06 |
| Connecting with DataSource Objects (0) | 2025.04.06 |
| Establishing a Connection (0) | 2025.04.06 |
| Processing SQL Statements with JDBC (0) | 2025.04.06 |