2026. 1. 4. 20:01ㆍSpring Microservice/Service Discovery
Where’s My Service?
클라우드 이전 시대의 서비스 위치 해석과 그 한계
마이크로서비스 아키텍처에서 가장 기본적이면서도 중요한 질문 중 하나는 이것입니다.
“내가 호출하려는 서비스는 지금 어디에 있는가?”
애플리케이션이 여러 서버에 분산된 리소스를 호출해야 할 때,
서비스의 물리적 위치(IP, 포트) 를 어떻게 찾을 것인지는 핵심적인 문제입니다.
이 챕터에서는 전통적인 서비스 위치 해석 방식이 무엇이었는지 살펴보고,
왜 이 방식이 클라우드 기반 마이크로서비스 환경에서는 더 이상 적합하지 않은지를 정리합니다.
1. 전통적인 서비스 위치 해석 모델
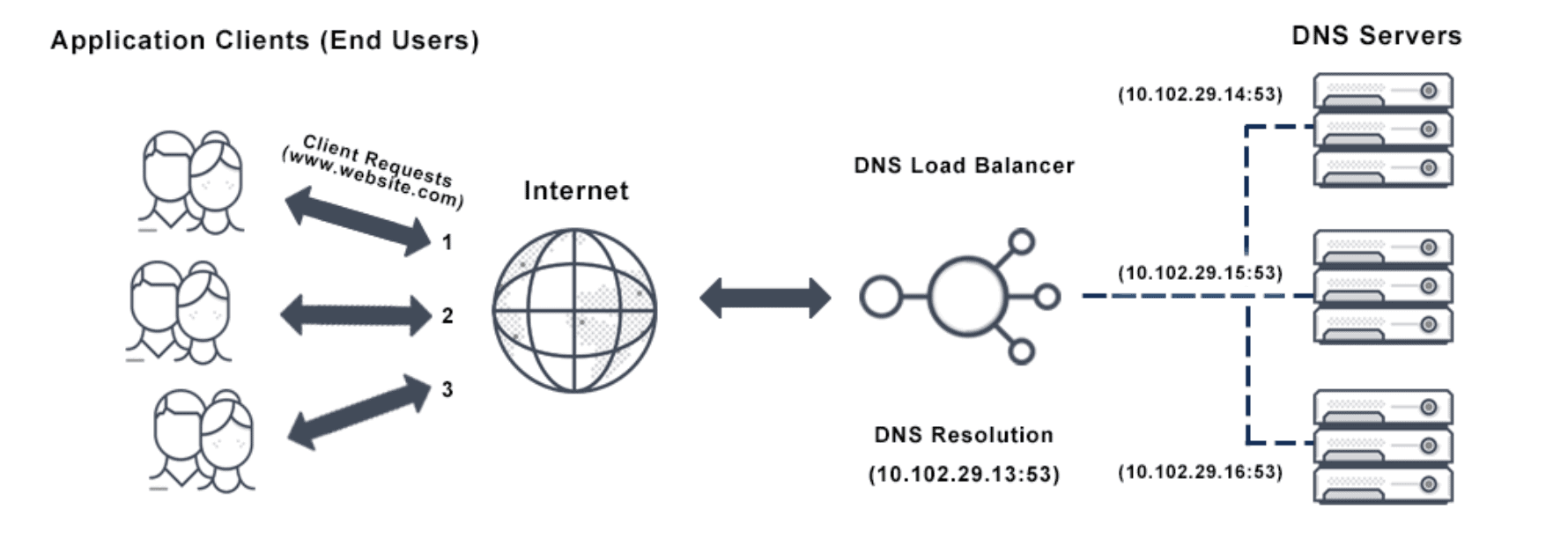


클라우드 이전의 환경에서 서비스 위치 해석(Service Location Resolution)은
대개 DNS + 네트워크 로드 밸런서 조합으로 해결되었습니다.
기본 동작 흐름은 다음과 같습니다.
- 서비스 소비자는 일반적인 DNS 이름으로 요청을 보냅니다.
- DNS는 해당 요청을 로드 밸런서로 해석합니다.
- 로드 밸런서는 요청 URL의 경로(path) 를 기준으로
- 내부 라우팅 테이블에서 실제 서비스 서버 목록을 조회합니다.
- 여러 서버 중 하나를 선택해 요청을 전달합니다.
이 구조에서 로드 밸런서는
- 상용 장비(예: F5)
- 또는 오픈소스 솔루션(예: HAProxy)
로 구현되는 경우가 일반적이었습니다.
2. 전통적 로드 밸런서의 운영 전제
이 모델은 다음과 같은 강한 전제 조건을 기반으로 합니다.
✅ 서버는 정적(static)이다
- 서비스가 배포된 애플리케이션 서버 수는 거의 변하지 않음
- 오토 스케일링 개념이 사실상 없음
✅ 서버는 영속적(persistent)이다
- 서버 장애 발생 시
- 동일한 IP
- 동일한 설정
- 동일한 상태
로 복구됨
✅ 고가용성은 Active / Standby 구조
- 주 로드 밸런서 장애 시
- 대기(Idle) 로드 밸런서가 IP를 인계받아 동작
이 구조는 기업 내부 데이터센터 환경에서는 꽤 안정적으로 동작했습니다.
3. 이 모델이 클라우드 환경에서 깨지는 이유
문제는 이 방식이 클라우드 기반 마이크로서비스 환경과는
근본적으로 맞지 않는다는 점입니다.
❌ 1. 중앙 로드 밸런서는 단일 장애 지점(SPOF)
로드 밸런서는 전체 인프라의 중앙 관문입니다.
- 로드 밸런서가 다운되면?
- 해당 로드 밸런서를 사용하는 모든 서비스가 중단
- 고가용성을 구성하더라도
- 여전히 중앙 집중형 병목 지점
❌ 2. 수평 확장의 구조적 한계
대부분의 전통적 로드 밸런서는 다음 제약을 가집니다.
- Hot-Standby 모델
- 실제 트래픽 처리 노드는 1대
- 처리량은 하드웨어 성능에 종속
- 라이선스는 고정 용량 기반
- 트래픽 증가 = 비용 폭증
➡️ 클라우드의 핵심 가치인 탄력적 확장과 정면으로 충돌합니다.
❌ 3. 정적 관리 방식
전통적인 로드 밸런서는 다음에 최적화되어 있습니다.
- 미리 정의된 서버 목록
- 변경이 거의 없는 라우팅 규칙
하지만 클라우드에서는?
- 서비스 인스턴스는 수시로 생성/종료
- IP 주소는 휘발성
- 컨테이너는 짧은 수명
그럼에도 로드 밸런서는:
- 중앙 DB에 라우팅 규칙 저장
- 신규 서비스 등록은 수동 또는 벤더 API
- 실시간 등록/해제에 부적합
❌ 4. 서비스 ↔ 물리 주소 매핑의 복잡성
로드 밸런서는 프록시로 동작합니다.
즉,
- 서비스 요청 URL
- 실제 서비스 인스턴스(IP, 포트)
사이의 번역 규칙을 사람이 정의해야 합니다.
이로 인해:
- 설정 복잡도 증가
- 배포 과정에 인적 개입 필수
- 서비스 인스턴스 기동 시 자동 등록 불가
4. 그렇다면 로드 밸런서는 쓸모없는가?
그렇지는 않습니다.
전통적 로드 밸런서는 여전히 중요한 역할을 합니다.
✅ 여전히 유효한 역할
- SSL/TLS 종료
- Ingress / Egress 트래픽 통제
- 네트워크 경계 보안
- PCI-DSS 같은 보안 규제 대응
특히 “최소 네트워크 접근 원칙(Least Network Access)” 을 구현하는 데 있어
로드 밸런서는 매우 강력한 도구입니다.
5. 클라우드 환경의 본질적인 요구
하지만 클라우드는 다음을 전제로 합니다.
- 인스턴스는 동적
- IP는 휘발성
- 장애는 일상적
- 확장은 자동화
이 환경에서 중앙 집중형 네트워크 장비는:
- 확장성에 한계가 있고
- 비용 효율적이지 않으며
- 변화 속도를 따라가지 못합니다.
6. 다음 단계: Service Discovery


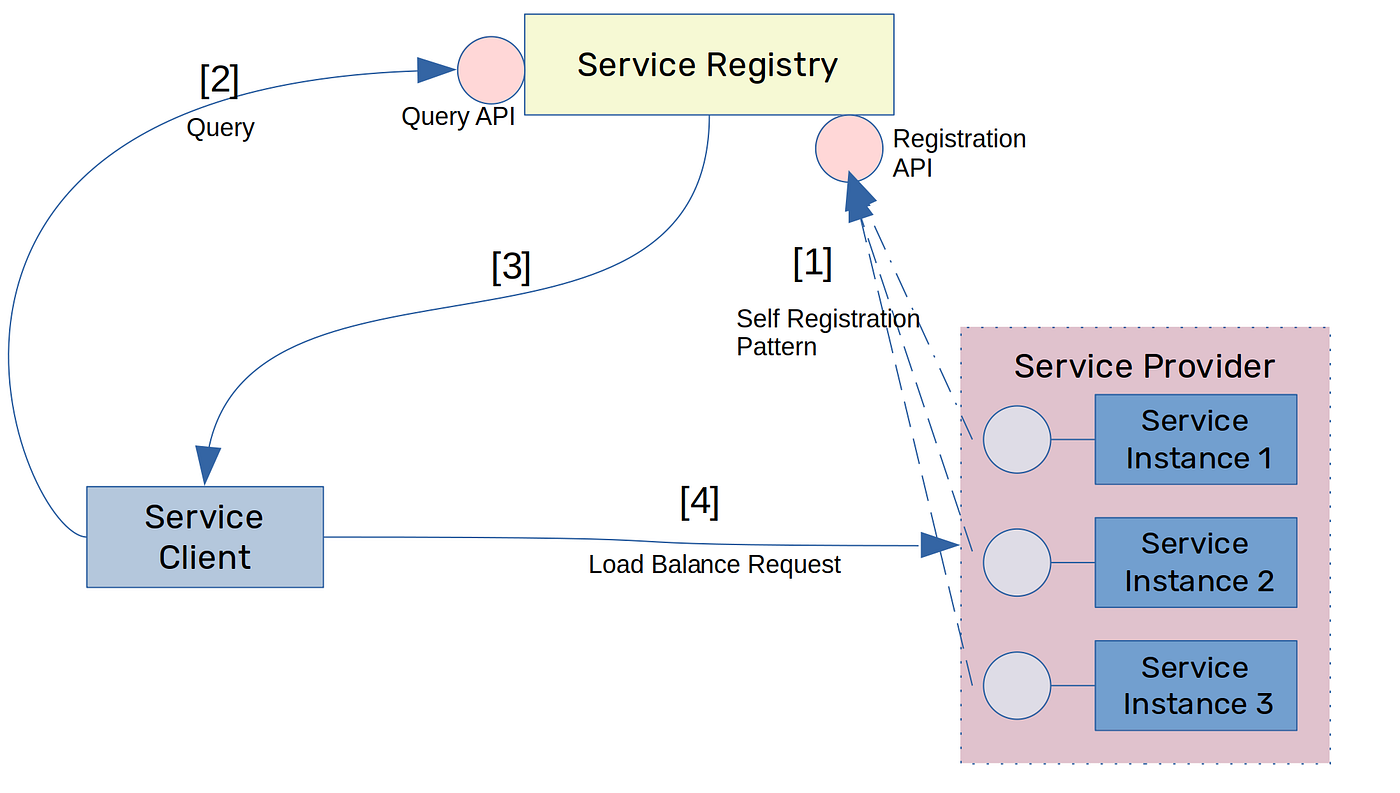
이러한 한계를 해결하기 위해 등장한 개념이 바로 Service Discovery입니다.
Service Discovery는:
- 서비스 인스턴스가 스스로 등록
- 종료 시 자동 해제
- 클라이언트 또는 플랫폼이 실시간 위치 조회
를 가능하게 합니다.
즉,
“중앙 로드 밸런서가 아니라
시스템 전체가 서비스 위치를 인지하는 구조”
로 패러다임이 전환된 것입니다.
마무리
전통적인 DNS + 로드 밸런서 모델은
정적 서버 + 기업 데이터센터 환경에서는 훌륭한 해법이었습니다.
하지만 클라우드 기반 마이크로서비스 환경에서는:
- 확장성
- 비용
- 자동화
- 장애 대응
모든 면에서 한계를 드러냅니다.
이제 서비스 위치 해석의 중심은
네트워크 장비가 아니라
애플리케이션과 플랫폼으로 이동하고 있습니다.
'Spring Microservice > Service Discovery' 카테고리의 다른 글
| Building our Spring Eureka service (0) | 2026.01.04 |
|---|---|
| Service discovery in the cloud (0) | 2026.01.04 |
| Feign Client (1) | 2025.03.14 |
| Load Balancer를 지원하는 Spring RestTemplate을 활용한 서비스 호출 (0) | 2025.03.14 |
| Spring Discovery Client (0) | 2025.03.14 |