2024. 4. 3. 15:11ㆍDocker
이 장에서는 다음을 다룹니다.
- 리소스 한도 설정
- 컨테이너 메모리 공유
- 사용자, 권한, 관리 권한 설정
- 특정 리눅스 기능에 대한 접근 권한 부여
- SELinux 및 AppArmor와 함께 작업하기
컨테이너는 전체 시스템 가상화가 아니라 격리된 프로세스 컨텍스트를 제공합니다. 이러한 의미 차이는 미묘해 보일 수 있지만, 영향은 극단적입니다. 제1장에서는 이러한 차이점을 약간 언급했습니다. 제2장부터 제5장까지는 Docker 컨테이너의 다른 격리 기능 세트를 각각 다루었습니다. 이 장에서는 남은 네 가지를 다루며, 시스템의 보안을 강화하는 정보를 포함하고 있습니다.
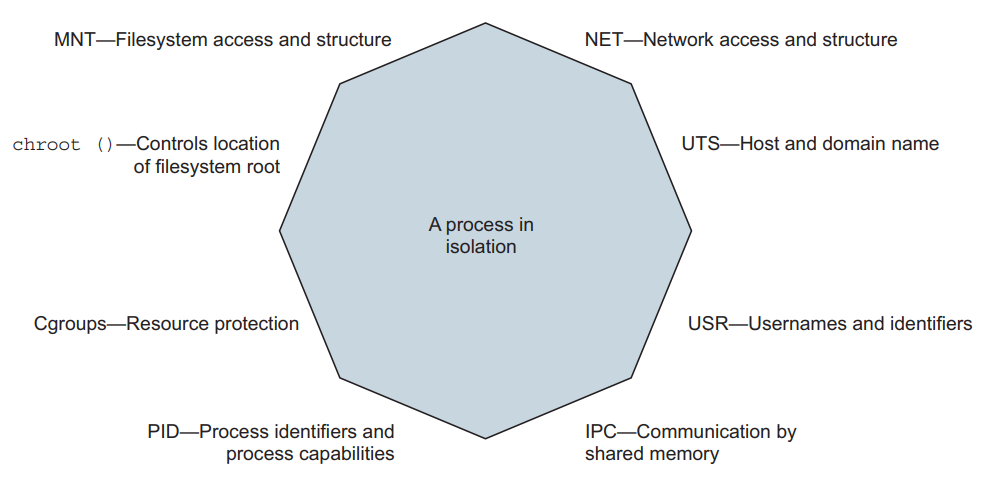
이 장에서 다루는 기능들은 소프트웨어를 실행할 때의 위험을 관리하거나 제한하는 데 중점을 둡니다. 이러한 기능들은 버그나 공격으로 인해 잘못 작동하는 소프트웨어가 컴퓨터를 반응하지 않게 만들 수 있는 리소스를 소비하는 것을 방지합니다. 컨테이너는 소프트웨어가 오직 당신이 기대하는 컴퓨팅 리소스를 사용하고 데이터에 접근하도록 도와줄 수 있습니다. 컨테이너에 리소스 할당량을 주고, 공유 메모리에 접근하며, 특정 사용자로 프로그램을 실행하고, 컨테이너가 컴퓨터에 할 수 있는 변경 유형을 제어하며, 다른 리눅스 격리 도구와 통합하는 방법을 배우게 됩니다. 이러한 주제 중 일부는 이 책의 범위를 벗어나는 리눅스 기능을 포함합니다. 이러한 경우에는, 그 목적과 기본 사용 예시에 대해 알려주려고 노력하며, Docker와 어떻게 통합할 수 있는지에 대해서도 설명합니다. 그림 6.1은 Docker 컨테이너를 구축하는 데 사용되는 여덟 개의 네임스페이스와 기능을 보여줍니다.
마지막으로 한 가지만 더 상기시켜 드립니다: Docker와 그것이 사용하는 기술은 진화하는 프로젝트입니다. 이 장의 예제들은 Docker 1.13 이상에서 작동해야 합니다. 이 장에서 소개된 도구들을 배운 후에, 가치 있는 것을 구축하러 갈 때는 발전, 개선 사항 및 새로운 최선의 방법을 확인하는 것을 잊지 마십시오.
6.1 Setting resource allowances
CPU의 메모리, 시간 등 물리적 시스템 리소스는 부족합니다. 컴퓨터에서 프로세스의 리소스 소비가 사용 가능한 물리적 리소스를 초과하면 프로세스에 성능 문제가 발생하고 실행이 중지될 수 있습니다.
강력한 격리를 생성하는 시스템 구축의 일부에는 개별 컨테이너에 대한 리소스 허용량 제공이 포함됩니다.
만약 여러분의 컴퓨터에서 다른 프로그램을 압도하지 않도록 하고 싶다면, 할 수 있는 가장 쉬운 일은 사용할 수 있는 리소스에 한계를 설정하는 것입니다. Docker를 사용하여 메모리, CPU 및 장치 리소스 할당량을 관리할 수 있습니다. 기본적으로 Docker 컨테이너는 무제한의 CPU, 메모리 및 장치 I/O 리소스를 사용할 수 있습니다. docker container create와 run 커맨드는 컨테이너에 사용 가능한 리소스를 관리하기 위한 플래그를 제공합니다.
6.1.1 Memory limits
컨테이너에 둘 수 있는 가장 기본적인 제한은 메모리 제한입니다. 이 제한은 컨테이너 내부 프로세스가 사용할 수 있는 메모리 양을 제한합니다. 메모리 제한은 한 컨테이너가 시스템의 모든 메모리를 할당하고 다른 프로그램이 필요로 하는 메모리를 고갈시키는 것을 방지하는 데 유용합니다. -m 또는 --memory 플래그를 docker container run 또는 docker container create 명령어에 사용하여 제한을 설정할 수 있습니다. 이 플래그는 값과 단위를 취합니다. 형식은 다음과 같습니다:
<number><optional unit> 여기서 단위는 b, k, m 또는 g입니다(ex, 256 m).
이 명령어의 맥락에서 b는 바이트, k는 킬로바이트, m은 메가바이트, g는 기가바이트를 나타냅니다. 이 새로운 지식을 사용하여 다른 예제에서 사용할 데이터베이스 애플리케이션을 시작하세요:
docker container run -d --name ch6_mariadb \
--memory 256m \ <-- Sets a memory constraint
--cpu-shares 1024 \
--cap-drop net_raw \
-e MYSQL_ROOT_PASSWORD=1234 \
mariadb:latest
이 명령어로 MariaDB라고 불리는 데이터베이스 소프트웨어를 설치하고 메모리 제한이 256 메가바이트인 컨테이너를 시작합니다. 명령어에 몇 가지 추가 플래그가 있는 것을 눈치챘을 수 있습니다. 이 장에서는 각각의 플래그를 다루지만, 이미 그것들이 무엇을 하는지 짐작할 수 있을 것입니다. 또 다른 주목할 점은 포트를 노출하거나 호스트의 인터페이스에 포트를 바인딩하지 않는다는 것입니다. 이 데이터베이스에 가장 쉽게 연결하는 방법은 호스트의 다른 컨테이너에서 링크하는 것입니다. 그 전에, 여기서 무슨 일이 일어나고 메모리 제한을 어떻게 사용하는지 완전히 이해하고 싶습니다.
메모리 제한에 대해 이해해야 할 가장 중요한 점은 예약이 아니라는 것입니다. 지정된 양의 메모리를 사용할 수 있다고 보장하지는 않습니다. 이는 단지 과소비로부터 보호해 주는 것일 뿐입니다. 또한 Linux 커널에 의한 메모리 계산 및 제한 적용 구현은 매우 효율적이므로 이 기능에 대한 런타임 오버헤드에 대해 걱정할 필요가 없습니다.
메모리 할당량을 설정하기 전에, 두 가지를 고려해야 합니다. 첫째, 실행하려는 소프트웨어가 제안된 메모리 할당량 아래에서 운영될 수 있습니까? 둘째, 실행하고 있는 시스템이 할당량을 지원할 수 있습니까?
첫 번째 질문은 종종 대답하기 어렵습니다. 이러한 날에 오픈 소스 소프트웨어와 함께 최소 요구 사항이 발표되는 것은 흔하지 않습니다. 그럼에도 불구하고, 여러분이 그것을 처리하도록 요청하는 데이터의 크기에 따라 소프트웨어의 메모리 요구 사항이 어떻게 확장되는지 이해해야 합니다. 좋든 싫든, 사람들은 종종 과대평가하고 시행착오를 통해 조정하는 경향이 있습니다. 하나의 옵션은 실제 워크로드와 함께 컨테이너에서 소프트웨어를 실행하고 docker stats 커맨드를 사용하여 컨테이너가 실제로 얼마나 많은 메모리를 사용하는지 확인하는 것입니다. 방금 시작한 mariadb 컨테이너의 경우, docker stats ch6_mariadb은 컨테이너가 약 100메가바이트의 메모리를 사용하고 있으며, 이는 256메가바이트 제한 내에 잘 맞습니다. 데이터베이스와 같은 메모리에 민감한 도구의 경우, 데이터베이스 관리자와 같은 숙련된 전문가들이 더 교육받은 추정치와 권장 사항을 제공할 수 있습니다. 그럼에도 불구하고, 질문은 종종 다음과 같은 또 다른 질문으로 대답됩니다: 당신이 가지고 있는 메모리는 얼마입니까? 그리고 그것이 두 번째 질문으로 이어집니다.
실행 중인 시스템이 할당량을 지원할 수 있습니까? 시스템에서 사용 가능한 메모리 양보다 큰 메모리 할당량을 설정할 수 있습니다. 스왑 공간(디스크로 확장된 가상 메모리)이 있는 호스트에서는 컨테이너가 할당량을 실현할 수 있습니다. 물리적 메모리 리소스보다 큰 할당량을 지정할 수 있습니다. 이러한 경우에는 시스템의 제한이 항상 컨테이너를 제한하고, 런타임 동작은 할당량을 지정하지 않은 것과 비슷할 것입니다.
마지막으로, 사용 가능한 메모리를 고갈시키면 소프트웨어가 실패하는 여러 가지 방법이 있다는 것을 이해하는 것이 중요합니다. 일부 프로그램은 메모리 접근 오류로 실패할 수 있으며, 다른 프로그램은 로깅에 메모리 부족 오류를 시작할 수 있습니다. Docker는 이 문제를 감지하거나 문제를 완화하려고 시도하지 않습니다. 최선을 다할 수 있는 것은 제2장에서 설명한 --restart 플래그를 사용하여 지정할 수 있는 재시작 로직을 적용하는 것입니다.
6.1.3 CPU
처리 시간도 메모리만큼 부족하지만, 부족의 효과는 실패가 아니라 성능 저하입니다. CPU 시간을 기다리고 있는 일시 중지된 프로세스는 여전히 올바르게 작동하고 있습니다. 그러나 중요한 지연 시간에 민감한 데이터 처리 프로그램, 수익을 창출하는 웹 애플리케이션, 또는 앱의 백엔드 서비스를 실행하는 느린 프로세스는 실패하는 것보다 더 나쁠 수 있습니다. Docker는 컨테이너의 CPU 리소스를 두 가지 방법으로 제한할 수 있게 합니다.
첫째, 컨테이너의 상대적 가중치를 다른 컨테이너들과 비교하여 지정할 수 있습니다. 리눅스는 이를 사용하여 컨테이너가 다른 실행 중인 컨테이너들에 비해 사용해야 하는 CPU 시간의 백분율을 결정합니다. 그 백분율은 컨테이너에 사용 가능한 모든 프로세서의 계산 주기 합계에 대한 것입니다.
컨테이너의 CPU 점유량을 설정하고 상대적 가중치를 정립하기 위해, docker container run과 docker container create는 --cpu-shares 플래그를 제공합니다. 제공된 값은 정수여야 합니다(따옴표로 묶지 않아야 함). CPU 점유량이 어떻게 작동하는지 보기 위해 다른 컨테이너를 시작해보세요:
docker container run -d -P --name ch6_wordpress \
--memory 512m \
--cpu-shares 512 \ <-- Sets a relative process weight
--cap-drop net_raw \
--link ch6_mariadb:mysql \
-e WORDPRESS_DB_PASSWORD=test \
wordpress:5.0.0-php7.2-apache
이 명령은 WordPress 버전 5.0을 다운로드하고 시작합니다. 이는 PHP로 작성되었으며 보안 위험에 적응하면서 어려움을 겪어온 소프트웨어의 훌륭한 예입니다. 여기에서는 몇 가지 추가적인 예방 조치와 함께 시작했습니다. 컴퓨터에서 실행 중인 것을 보고 싶다면, 서비스가 실행 중인 포트 번호(<port>라고 합니다)를 얻기 위해 docker port ch6_wordpress를 사용하고 웹 브라우저에서 http://localhost:<port>를 엽니다. Docker Machine을 사용하는 경우, Docker가 실행 중인 가상 머신의 IP 주소를 결정하기 위해 docker-machine ip를 사용해야 합니다. 그 값을 가지고 있다면, 앞서의 URL에서 localhost를 그 값으로 대체하세요.
MariaDB 컨테이너를 시작할 때, 그것의 상대적 가중치(cpu-shares)를 1024로 설정했고, WordPress의 상대적 가중치를 512로 설정했습니다. 이 설정은 MariaDB 컨테이너가 WordPress의 한 사이클마다 두 CPU 사이클(스레드 CPU 타임 슬라이스 스케줄링 사이클)을 얻는 시스템을 만듭니다. 만약 세 번째 컨테이너를 시작하고 그것의 --cpu-shares 값을 2048로 설정한다면, 그것은 CPU 사이클의 절반을 얻게 되고, MariaDB와 WordPress는 그 전과 같은 비율로 나머지 절반을 나누게 됩니다. 그림 6.2는 시스템의 총 가중치에 기반하여 부분이 어떻게 변하는지 보여줍니다.

CPU 점유량은 메모리 제한과 달리 CPU 시간에 대한 경쟁이 있을 때만 적용됩니다. 다른 프로세스와 컨테이너가 idle 상태일 경우, 컨테이너는 제한을 훨씬 초과하여 사용할 수 있습니다. 이 접근 방식은 CPU 시간이 낭비되지 않도록 하고 다른 프로세스가 CPU를 필요로 할 때 제한된 프로세스가 양보하도록 합니다. 이 도구의 의도는 컴퓨터를 압도하는 하나 또는 일련의 프로세스를 방지하는 것이지, 그 프로세스의 성능을 저해하는 것이 아닙니다. 디폴트값은 컨테이너를 제한하지 않으며, 머신이 다른 용도로 유휴 상태인 경우 100%의 CPU를 사용할 수 있습니다.
이제 cpu-shares의 CPU를 비례적으로 할당하는 방법을 배웠으므로, 컨테이너가 사용하는 CPU의 총량을 제한하는 방법을 제공하는 cpus 옵션을 소개하겠습니다. cpus 옵션은 컨테이너가 사용할 수 있는 CPU 리소스의 할당량을 리눅스 완전 공정 스케줄러(CFS: Completely Fair Scheduler )를 구성하여 할당합니다. Docker는 컨테이너가 사용할 수 있어야 하는 CPU 코어의 수로 할당량을 표현할 수 있게 도와줍니다. CPU 할당량은 기본적으로 매 100ms마다 할당되고, 집행되며, 최종적으로 새로 고침됩니다. 컨테이너가 모든 CPU 할당량을 사용하면, 다음 측정 기간이 시작될 때까지 CPU 사용이 제한됩니다. 다음 명령은 앞서의 WordPress 예제가 최대 0.75 CPU 코어를 소비하도록 할 것입니다:
docker container run -d -P --name ch6_wordpress \
--memory 512m \
--cpus 0.75 \
--cap-drop net_raw \
--link ch6_mariadb:mysql \
-e WORDPRESS_DB_PASSWORD=test \
wordpress:php8.3
Docker가 노출하는 또 다른 기능은 컨테이너를 특정 CPU 세트에 할당하는 능력입니다. 대부분의 현대 하드웨어는 멀티코어 CPU를 사용합니다. 대략적으로 말해서, CPU는 코어 개수 만큼의 CPU 명령어를 병렬로 처리할 수 있습니다. 이는 같은 컴퓨터에서 많은 프로세스를 실행할 때 특히 유용합니다.
컨텍스트 스위치는 한 프로세스의 실행에서 다른 프로세스로 변경하는 작업입니다. 컨텍스트 스위칭은 비용이 많이 들며 시스템의 성능에 눈에 띄는 영향을 줄 수 있습니다. docker container run 또는 docker container create에서 --cpuset-cpus 플래그를 사용하여 컨테이너가 특정 세트의 CPU 코어에서만 실행되도록 제한할 수 있습니다.
CPU 세트 제한을 동작 중에 볼 수 있습니다. 머신의 한 코어를 스트레스 받게 하고 CPU 워크로드를 검사합니다:
⦁ 단일 CPU에 제한된 컨테이너를 시작하고 부하 생성기를 실행합니다.
docker container run -d \
--cpuset-cpus 0 \
--name ch6_stresser intheeast0305/ch6_stresser
⦁ 부하가 걸린 CPU의 부하를 관찰하기 위해 컨테이너를 시작합니다.
docker container run -it --rm dockerinaction/ch6_htop
두 번째 커맨드를 실행하면, htop이 실행 중인 프로세스와 사용 가능한 CPU의 워크로드를 표시합니다. ch6_stresser 컨테이너는 30초 후에 실행을 멈추므로, 이 실험을 할 때 지체하지 않는 것이 중요합니다. htop을 사용을 마쳤다면, Q를 눌러 종료하세요. 계속하기 전에, ch6_stresser라는 컨테이너를 종료하고 제거하는 것을 잊지 마세요:
docker rm -vf ch6_stresser
우리는 처음 이것을 사용했을 때 이것이 흥미로웠습니다. 최상의 이해를 위해, --cpuset-cpus 플래그에 대해 다른 값을 사용하여 이 실험을 몇 번 반복하세요. 그렇게 하면, 프로세스가 다른 코어나 다른 코어 세트에 할당되는 것을 볼 수 있습니다. 값은 목록이나 범위일 수 있습니다:
- 0, 1, 2—CPU의 첫 세 코어를 포함하는 목록
- 0-2—CPU의 첫 세 코어를 포함하는 범위
6.1.3 Access to devices
디바이스는 우리가 다룰 마지막 자원 유형입니다. 디바이스에 대한 접근 제어는 메모리와 CPU 제한과는 다릅니다. 컨테이너 내부에서 호스트의 디바이스에 접근할 수 있도록 제공하는 것은 제한을 설정하는 것이라기보다는 자원 승인 제어(resource-authorization control)와 비슷합니다.
리눅스 시스템에는 하드 드라이브, 광학 드라이브, USB 드라이브, 마우스, 키보드, 사운드 디바이스, 웹캠 등 다양한 디바이스가 있습니다. 컨테이너는 기본적으로 호스트의 일부 디바이스에 접근할 수 있으며, Docker는 각 컨테이너에 대해 별도로 다른 디바이스를 생성합니다. 이는 가상 터미널이 사용자에게 전용 입력 및 출력 디바이스를 제공하는 방식과 유사하게 작동합니다.
때로는 특정 컨테이너와 호스트 간에 다른 디바이스를 공유하는 것이 중요할 수 있습니다. 예를 들어, 컴퓨터 비전 소프트웨어를 실행하는 경우 웹캠에 접근이 필요할 수 있습니다. 이 경우, 소프트웨어를 실행하는 컨테이너에 시스템에 연결된 웹캠 디바이스에 대한 접근 권한을 부여해야 합니다. 이를 위해 --device 플래그를 사용하여 새 컨테이너에 마운트할 디바이스를 지정할 수 있습니다. 다음 예제는 /dev/video0에 있는 웹캠을 새 컨테이너 내 동일한 위치로 매핑하는 방법을 보여줍니다. 이 예제를 실행하려면 시스템에 /dev/video0 위치에 웹캠이 있어야만 작동합니다.
docker container run -it --rm \
--device /dev/video0:/dev/video0 \ <--- Mounts video0
ubuntu:16.04 ls -al /dev
제공된 값[ --device /dev/video0:/dev/video0 ]은 호스트 운영 체제의 디바이스 파일과 새 컨테이너 내부 위치 간의 매핑이어야 합니다. 디바이스 플래그[--device]는 여러 번 설정하여 다양한 디바이스에 대한 접근 권한을 부여할 수 있습니다.
이러한 디바이스 접근 방식은 맞춤형 하드웨어나 독점 드라이버를 사용하는 상황에서 유용하며, 호스트 운영 체제를 수정하는 것보다 선호됩니다.
6.2 Sharing memory
Linux는 동일한 컴퓨터에서 실행 중인 프로세스 간의 메모리를 공유하기 위한 몇 가지 도구를 제공합니다. 이러한 형태의 프로세스 간 통신(IPC)은 메모리 속도로 수행됩니다. 이는 네트워크나 파이프 기반 IPC로 인한 지연이 소프트웨어 성능을 요구 사항 이하로 떨어뜨릴 때 자주 사용됩니다. 메모리 기반 IPC의 가장 좋은 예는 과학 계산과 PostgreSQL 같은 일부 인기 있는 데이터베이스 기술에서 찾아볼 수 있습니다.
Docker는 디폴트로 각 컨테이너에 대해 고유한 IPC 네임스페이스를 생성합니다. Linux IPC 네임스페이스는 이름이 지정된 공유 메모리 블록과 세마포어, 메시지 큐와 같은 공유 메모리 원시 요소[primitivs]를 분할합니다. 이러한 것이 무엇인지 잘 몰라도 괜찮습니다. Linux 프로그램이 프로세싱를 조율하기 위해 사용하는 도구라고만 알아두면 됩니다. IPC 네임스페이스는 하나의 컨테이너에 있는 프로세스가 호스트 또는 다른 컨테이너의 메모리에 접근하지 못하도록 방지합니다.
6.2.1 Sharing IPC primitives between containers
우리는 dockerinactionch6_ipc라는 이미지를 생성했으며, 이 이미지에는 프로듀서와 컨슈머가 모두 포함되어 있습니다. 이들은 공유 메모리를 사용해 통신합니다. 다음 내용은 이들을 별도의 컨테이너에서 실행할 때 발생하는 문제를 이해하는 데 도움을 줄 것입니다.
docker container run -d -u nobody --name ch6_ipc_producer \ <--- Starts producer
--ipc shareable \
intheeast0305/ch6_ipc -producer
docker container run -d -u nobody --name ch6_ipc_consumer \ <--- Starts consumer
intheeast0305/ch6_ipc -consumer
이 명령어들은 두 개의 컨테이너를 시작합니다. 첫 번째 컨테이너는 메시지 큐를 생성하고 해당 큐에서 메시지를 브로드캐스트하기 시작합니다. 두 번째 컨테이너는 메시지 큐에서 메시지를 가져와 로그에 기록해야 합니다. 각각의 컨테이너가 무엇을 하고 있는지 확인하려면 다음 명령어를 사용하여 각 컨테이너의 로그를 검사할 수 있습니다.
docker logs ch6_ipc_producer
docker logs ch6_ipc_consumer
시작한 컨테이너에서 문제가 발생한 것을 확인했습니다. consumer는 큐에서 메시지를 전혀 확인하지 못합니다. 각 프로세스는 공유 메모리 리소스를 식별하기 위해 동일한 키를 사용하지만, 서로 다른 메모리를 참조합니다. 그 이유는 각 컨테이너가 자체 공유 메모리 네임스페이스를 가지고 있기 때문입니다.
다른 컨테이너에서 공유 메모리를 사용하는 프로그램을 실행해야 하는 경우, --ipc 플래그를 사용해 해당 컨테이너들의 IPC 네임스페이스를 연결해야 합니다. --ipc 플래그는 타겟 컨테이너와 동일한 IPC 네임스페이스에 새 컨테이너를 생성하는 컨테이너 모드를 가지고 있습니다. 이는 5장에서 다룬 --network 플래그와 유사하게 작동합니다. 그림 6.3은 컨테이너와 해당 네임스페이스화된 공유 메모리 풀 간의 관계를 보여줍니다.
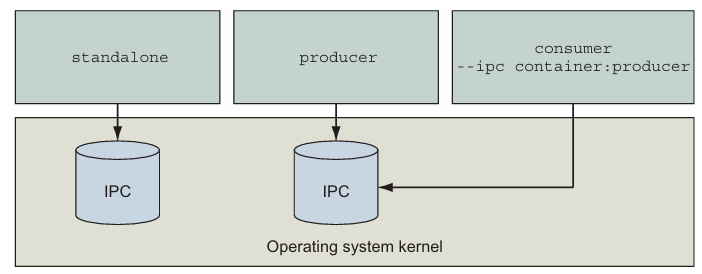
다음 커맨드를 사용하여 IPC 네임스페이스가 연결된 것을 직접 테스트해보세요:
$ docker container rm -v ch6_ipc_consumer <---Removes original consumer
docker container run -d --name ch6_ipc_consumer \ <--- Starts new consumer
--ipc container:ch6_ipc_producer \ <--- Joins IPC namespace
intheeast0305/ch6_ipc -consumer
위 커맨드들은 consumer 컨테이너를 다시 빌드하고 ch6_ipc_producer 컨테이너의 IPC 네임스페이스를 재사용합니다. 이번에는 consumer가 서버가 데이터를 쓰고 있는 동일한 메모리 위치에 접근할 수 있어야 합니다. 아래 커맨드를 사용하여 각 컨테이너의 로그를 확인함으로써 이것이 작동하는 것을 확인할 수 있습니다:
docker logs ch6_ipc_producer
docker logs ch6_ipc_consumer
다음으로 진행하기 전에 실행 중인 컨테이너를 정리하는 것을 잊지 마세요:
docker rm -vf ch6_ipc_producer ch6_ipc_consumer- The v option will clean up volumes.
- The f option will kill the container if it is running.
- The rm command takes a list of containers.
컨테이너의 공유 메모리 네임스페이스를 재사용하는 것은 명백한 보안 상의 영향을 미칩니다. 그러나 필요할 경우 이 옵션을 사용할 수 있습니다. 컨테이너 간에 메모리를 공유하는 것은 호스트와 메모리를 공유하는 것보다 더 안전한 대안입니다. 호스트 메모리를 공유하는 것은 --ipc=host 옵션을 사용하여 가능하지만, 이는 Docker의 기본 보안 정책과 모순되기 때문에 최신 Docker 배포판에서는 어렵습니다.
이 예제의 소스 코드를 자유롭게 확인해 보세요. 이는 보기에는 다소 조잡하지만 간단한 C 프로그램입니다. 해당 소스 코드는 Docker Hub에서 이미지 페이지에 연결된 소스 저장소에서 확인할 수 있습니다.
6.3 Understanding users
Docker는 기본적으로 이미지 메타데이터에 의해 지정된 사용자를 기준으로 컨테이너를 시작하며, 이는 종종 root 사용자입니다. root 사용자는 컨테이너 상태에 거의 완전한 권한을 가지며, root 사용자로 실행되는 모든 프로세스는 해당 권한을 상속받습니다. 따라서 이러한 프로세스 중 하나에 버그가 있으면 컨테이너에 손상을 줄 가능성이 있습니다.
이러한 문제를 제한하는 방법은 여러 가지가 있지만, 가장 효과적인 방법은 root 사용자를 사용하지 않는 것입니다. 물론 합리적인 예외 상황도 존재합니다. 때로는 root 사용자를 사용하는 것이 가장 좋은 방법이거나 유일한 선택일 수 있습니다. 예를 들어 이미지를 빌드하거나 다른 옵션이 없을 때 런타임에 root 사용자를 사용할 수 있습니다. 또한 컨테이너 내부에서 시스템 관리 소프트웨어를 실행해야 하는 경우도 있습니다. 이러한 경우 프로세스는 컨테이너뿐만 아니라 호스트 운영 체제에 대한 권한도 필요합니다.
이 섹션에서는 이러한 문제에 대한 다양한 해결책을 다룹니다.
6.3.1 Working with the run-as user
컨테이너를 생성하기 전에 디폴트로 사용될 사용자 이름(및 사용자 ID)을 알 수 있다면 좋을 것입니다. 디폴트 값은 이미지에 의해 지정됩니다. 현재 Docker Hub에서는 디폴트 사용자와 같은 속성을 확인할 방법이 없습니다. 하지만 docker inspect 명령어를 사용하여 이미지 메타데이터를 확인할 수 있습니다.
2장에서 다뤘던 것처럼, inspect 서브커맨드는 특정 컨테이너나 이미지의 메타데이터를 표시합니다. 이미지를 가져오거나 생성한 후에는 아래 명령어를 사용하여 컨테이너에서 사용하는 디폴트 사용자 이름을 확인할 수 있습니다.
$ docker image pull busybox:1.37
$ docker image inspect busybox:1.37 <--- Display all of busybox's metadata
$ docker inspect --format "{{.Config.User}}" busybox:1.37 <--- Show only the run as user
defined by the busybox image
result가 Empty라면, 컨테이너는 기본적으로 root 사용자로 실행됩니다. 비어 있지 않다면, 이미지 작성자가 디폴트 특정 사용자 실행(run-as user)를 명시적으로 설정했거나, 컨테이너를 생성할 때 특정 사용자 실행을 설정한 것입니다. 두 번째 명령에서 사용된 --format 또는 -f 옵션은 출력 형식을 지정할 템플릿을 설정할 수 있게 해줍니다. 이 경우, 문서의 Config 속성의 User 필드를 선택했습니다. 이 값은 유효한 Go 템플릿일 수 있으므로, 필요하다면 결과를 창의적으로 변형할 수도 있습니다.
이 접근 방식에는 한 가지 문제가 있습니다. 이미지를 시작할 때 사용하는 엔트리포인트나 커맨드에 의해 특정 사용자 실행(run-as user)이 변경될 수 있습니다. 이러한 것들은 부트(boot) 또는 초기화(init) 스크립트라고도 합니다. docker inspect가 리턴하는 메타데이터에는 컨테이너가 시작될 때의 초기 설정만 포함됩니다. 따라서 사용자가 변경되더라도 이 정보는 반영되지 않습니다.
현재 이 문제를 해결할 수 있는 유일한 방법은 이미지 내부를 확인하는 것입니다. 이미지를 다운로드한 후 파일을 확장하여 메타데이터와 초기화 스크립트를 직접 조사할 수 있지만, 이는 시간이 많이 걸리고 실수하기 쉽습니다. 지금으로서는 디폴트 사용자를 확인하기 위해 간단한 실험을 실행하는 것이 더 나을 수 있습니다. 이 방법은 첫 번째 문제는 해결할 수 있지만, 두 번째 문제는 해결하지 못합니다.
docker container run --rm --entrypoint "" busybox:1.37 whoami <--- Outputs: root
docker container run --rm --entrypoint "" busybox:1.37 id <--- Outputs: uid=0(root)
gid=0(root) groups=10(wheel)
다음은 이미지(이 경우 busybox:1.37)의 디폴트 사용자를 확인하기 위해 사용할 수 있는 두 가지 명령어를 보여줍니다. whoami와 id 명령어는 대부분의 Linux 배포판에서 공통적으로 사용되므로, 특정 이미지에서도 사용할 수 있는 가능성이 높습니다. 두 번째 커맨드(id)는 특정 사용자 실행(run-as user)의 이름과 ID 세부 정보를 모두 보여주기 때문에 더 우수합니다.
이 두 커맨드 모두 컨테이너의 진입점을 설정 해제하는 데 주의해야 합니다. 이렇게 하면 이미지 이름 뒤에 지정된 커맨드가 컨테이너에서 실행되는 커맨드가 맞는지 확인할 수 있습니다. 이들은 퍼스트 클래스 이미지 메타데이터 도구를 대체할 수 있는 부실한 도구이지만, 해당 작업은 완료되었습니다. 그림 6.4에서 두 root 사용자 간의 짧은 대화를 고려해 보겠습니다.
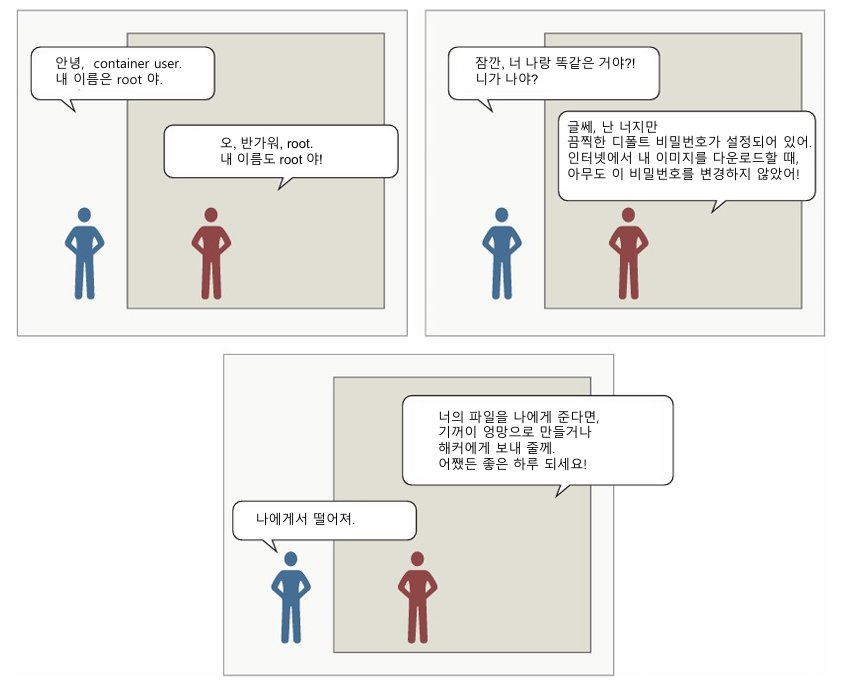
컨테이너를 생성할 때 특정 사용자 실행(run-as user)을 변경하면 디폴트 사용자 문제를 완전히 피할 수 있습니다. 그러나 이를 사용할 때의 특징은, 사용하려는 사용자가 사용 중인 이미지에 존재해야 한다는 점입니다. 다양한 Linux 배포판에는 사전 정의된 사용자가 서로 다르게 포함되어 있으며, 일부 이미지 작성자는 이를 축소하거나 확장하기도 합니다. 이미지에서 사용 가능한 사용자의 목록은 다음 커맨드를 사용해 확인할 수 있습니다:
docker container run --rm busybox:1.29 awk -F: '$0=$1' /etc/passwd
여기서 자세히 다루지는 않겠지만, Linux 사용자 데이터베이스는 /etc/passwd에 위치한 파일에 저장됩니다. 위 커맨드는 컨테이너 파일 시스템에서 해당 파일을 읽어 사용자 이름 목록을 가져옵니다. 사용할 사용자를 식별한 후, 특정 실행 사용자를 지정하여 새 컨테이너를 생성할 수 있습니다. Docker는 docker container run 및 docker container create에서 사용자 설정을 위해 --user 또는 -u 플래그를 제공합니다. 다음은 사용자를 nobody로 설정하는 예제입니다:
$ docker container run --rm \
> --user nobody \ <--- Sets run-as user to nobody
> busybox:1.37 id <--- Outputs: uid=65534(nobody)
gid=65534(nogroup)이 커맨드는 nobody 사용자를 사용했습니다. 이 사용자는 제한된 권한 시나리오(예: 애플리케이션 실행)에 사용하도록 설계된 공통 사용자입니다. 이것은 단순한 예제일 뿐입니다. 여기서 이미지에 정의된 어떤 사용자 이름도 사용할 수 있으며, root도 포함됩니다. 이는 -u 또는 --user 플래그를 사용할 때 할 수 있는 작업의 극히 일부에 불과합니다. 해당 값은 사용자나 그룹 쌍을 모두 허용합니다. 사용자를 이름으로 지정하면, 그 이름은 컨테이너의 passwd 파일에 지정된 사용자 ID(UID)로 변환됩니다. 그런 다음 해당 UID로 명령이 실행됩니다. 이로 인해 또 다른 기능이 생깁니다. --user 플래그는 사용자와 그룹 이름 또는 ID도 허용합니다. 이름 대신 ID를 사용할 때는 옵션이 더욱 확장됩니다:
$ docker container run --rm \
> -u nobody:nogroup \ <--- Sets run-as user to nobody and group to nogroup
> busybox:1.37 id <--- Outputs: uid=65534(nobody) gid=65534(nogroup)
$ docker container run --rm
> -u 10000:20000 \ <--- Sets UID and GID
> busybox:1.37 <--- Outputs: uid=10000 gid=20000
두 번째 커맨드는 컨테이너에 존재하지 않는 사용자와 그룹으로 실행 사용자 및 그룹을 설정하여 새 컨테이너를 시작합니다. 이 경우, ID가 사용자 또는 그룹 이름으로 확인되지 않지만, 파일 권한은 사용자와 그룹이 존재하는 것처럼 작동합니다. 컨테이너에 패키징된 소프트웨어가 어떻게 구성되었는지에 따라, 실행 사용자를 변경하면 문제가 발생할 수 있습니다. 그렇지 않으면, 이것은 제한된 권한으로 애플리케이션을 실행하고 파일 권한 문제를 해결하는 것을 단순화할 수 있는 강력한 기능입니다.
런타임 구성에 자신감을 가지는 가장 좋은 방법은 신뢰할 수 있는 소스에서 이미지를 가져오거나 직접 이미지를 빌드하는 것입니다. 표준 Linux 배포판과 마찬가지로, 기본 비root 사용자를 root 사용자로 전환하거나 인증 없이 root 계정에 접근할 수 있는 suid 활성화 프로그램을 사용하는 것과 같은 악의적인 작업이 가능합니다. suid 예제의 위협은 섹션 6.6에서 설명된 사용자 지정 컨테이너 보안 옵션, 특히 --security-opt no-new-privileges 옵션을 사용하여 완화할 수 있습니다. 그러나 이는 문제를 해결하기에는 배포 프로세스에서 너무 늦습니다. 완전한 Linux 호스트와 마찬가지로, 이미지는 최소 권한의 원칙을 사용하여 분석하고 보안을 유지해야 합니다. 다행히도 Docker 이미지는 애플리케이션 실행에 필요한 부분만 포함하고 나머지는 제외하도록 목적에 맞게 제작할 수 있습니다. 7장, 8장, 10장에서 최소 애플리케이션 이미지를 생성하는 방법을 다룹니다.
6.3.2 Users and volumes
이제 컨테이너 내부의 사용자와 호스트 시스템의 사용자가 동일한 사용자 ID 공간을 공유한다는 것을 알았으니, 이 둘이 어떻게 상호작용할 수 있는지 배워야 합니다. 이러한 상호작용의 주요 이유는 볼륨에 있는 파일의 파일 권한 때문입니다. 예를 들어, Linux 터미널을 실행 중이라면 다음 커맨드를 직접 사용할 수 있습니다. 그렇지 않다면 docker-machine ssh 명령어를 사용하여 Docker Machine 가상 머신의 셸에 접속해야 합니다.
$ echo "e=mc^2" > garbage <-- Creates new file
on your host
$ chmod 600 garbage <--- Makes file readable
only by its owner
$ sudo chown root garbage <--- Makes file owned by root
(assuming you have sudo access)
$ docker container run --rm -v "$(pwd)"/garbage:/test/garbage \
> -u nobody \
> ubuntu:24.04 cat /test/garbage <--- Tries to read
file as nobody
$ docker container run --rm -v "$(pwd)"/garbage:/test/garbage \
> -u root ubuntu:24.04 cat /test/garbage <--- Tries to read file as
"container root"
# Outputs: "e=mc^2"
# cleanup that garbage
$ sudo rm -f garbage
마지막에서 두 번째 Docker 명령어는 "Permission denied"라는 오류 메시지와 함께 실패해야 합니다. 그러나 마지막 Docker 명령어는 성공하며, 첫 번째 명령어에서 생성한 파일의 내용을 표시해야 합니다. 이는 볼륨에 있는 파일의 권한이 컨테이너 내부에서도 존중된다는 것을 의미합니다. 또한, 사용자 ID 공간이 공유된다는 것을 보여줍니다. 호스트의 root와 컨테이너의 root는 모두 사용자 ID 0을 공유합니다. 따라서 컨테이너의 ID 65534를 가진 nobody 사용자는 호스트에서 root가 소유한 파일에 접근할 수 없지만, 컨테이너의 root 사용자는 접근할 수 있습니다.
컨테이너에서 파일에 접근 가능하게 하고 싶지 않다면, 해당 파일을 볼륨을 통해 그 컨테이너에 마운트하지 마십시오.
이 예제의 긍정적인 점은 파일 권한이 존중되는 방식을 확인했다는 것이며, 이는 실질적이고도 일상적인 운영 문제를 해결할 수 있는 방법을 보여줍니다. 예를 들어, 볼륨에 기록된 로그 파일을 어떻게 처리할 것인가 하는 문제를 생각해볼 수 있습니다.
4장에서 설명한 대로, 선호되는 방법은 볼륨을 사용하는 것입니다. 하지만 이 경우에도 파일 소유권과 권한 문제를 고려해야 합니다. 예를 들어, 사용자 ID 1001로 실행되는 프로세스가 볼륨에 로그를 기록하고, 다른 컨테이너가 사용자 ID 1002로 해당 파일에 접근하려고 하면, 파일 권한이 작업을 방해할 수 있습니다.
이 장애물을 극복하는 한 가지 방법은 실행 중인 사용자의 사용자 ID를 구체적으로 관리하는 것입니다. 컨테이너를 실행할 사용자의 사용자 ID를 설정하여 이미지를 미리 편집하거나, 원하는 사용자와 그룹 ID(GID)를 사용할 수 있습니다.
$ mkdir logFiles
$ sudo chown 2000:2000 logFiles <--- Sets ownership of directory
to desired user and group
<--- Writes important log file --->
$ docker container run --rm -v "$(pwd)"/logFiles:/logFiles \
> -u 2000:2000 ubuntu:16.04 \ <--- Sets UID:GID to 2000:2000
> /bin/bash -c "echo This is important info > /logFiles/important.log"
<--- Appends to log from another container --->
$ docker container run --rm -v "$(pwd)"/logFiles:/logFiles \
> -u 2000:2000 ubuntu:16.04 \ <--- Also sets UID:GID to 2000:2000
> /bin/bash -c "echo More info >> /logFiles/important.log"
$ sudo rm –r logFiles
이 예제를 실행한 후, 사용자 ID 2000이 소유한 디렉토리에 파일이 작성될 수 있음을 확인할 수 있습니다. 뿐만 아니라, 해당 디렉토리에 쓰기 권한이 있는 사용자나 그룹을 사용하는 컨테이너는 파일을 작성하거나 동일한 파일에 접근할 수 있습니다(권한이 허용된다면). 이 방법은 파일 읽기, 쓰기, 실행에 모두 사용할 수 있습니다.
특히 언급할 만한 사용자 ID와 파일 시스템 상호작용이 있습니다. 기본적으로 Docker 데몬 API는 호스트의 /var/run/docker.sock에 위치한 UNIX 도메인 소켓을 통해 접근할 수 있습니다. 도메인 소켓은 파일 시스템 권한으로 보호되어 있어, root 사용자와 docker 그룹의 구성원만 Docker 데몬에 명령을 보내거나 데이터를 가져올 수 있습니다. 일부 프로그램은 Docker 데몬 API와 직접 상호작용하도록 설계되어 있으며, 컨테이너를 검사하거나 실행하기 위한 명령을 보낼 수 있습니다.
Docker API의 강력함
Docker 커맨드라인 프로그램은 거의 모든 상호작용을 Docker 데몬 API를 통해 수행합니다. 이는 Docker API가 얼마나 강력한지를 보여줍니다. Docker API에 읽기와 쓰기가 가능한 모든 프로그램은 Docker 커맨드라인에서 수행할 수 있는 모든 작업을 할 수 있습니다. 단, 이는 Docker의 Authorization 플러그인 시스템에 의해 제한됩니다.
컨테이너를 관리하거나 모니터링하는 프로그램은 종종 Docker 데몬의 엔드포인트에 대한 읽기 또는 쓰기 권한이 필요합니다. Docker API에 대한 읽기 및 쓰기 권한은 보통 관리 프로그램을 docker.sock에 읽기 또는 쓰기 권한이 있는 사용자나 그룹으로 실행하고, /var/run/docker.sock을 컨테이너에 마운트하여 제공됩니다.
docker container run --rm -it
–v /var/run/docker.sock:/var/run/docker.sock:ro \ (1)
-u root monitoringtool (2)(1) Binds docker .sock from host into container as a read-only file
(2) Container runs as root user, aligning with file permission on host
위 예제는 권한이 있는 프로그램 작성자들이 비교적 흔히 요청하는 사항을 보여줍니다. 시스템에서 어떤 사용자 또는 프로그램이 Docker 데몬을 제어할 수 있는지 주의해야 합니다. 사용자가 Docker 데몬을 제어할 수 있다면, 이는 사실상 호스트의 root 계정을 제어할 수 있다는 의미이며, 어떠한 프로그램도 실행하거나 파일을 삭제할 수 있습니다.
6.3.3 Introduction to the Linux user namespace and UID remapping
Linux의 user(USR) namespace는 하나의 네임스페이스에서 다른 네임스페이스로 사용자를 매핑합니다. user 네임스페이스는 프로세스 식별자(PID) 네임스페이스처럼 작동하며, 컨테이너의 UID와 GID를 호스트의 기본 사용자 ID와 분리합니다.
기본적으로 Docker 컨테이너는 USR 네임스페이스를 사용하지 않습니다. 이는 컨테이너에서 특정 user ID(숫자, 이름이 아님)를 사용하는 경우, 해당 ID가 호스트 시스템의 user ID와 동일하다면 해당 user는 호스트 파일 시스템에서 동일한 권한을 갖는다는 의미입니다. 이것이 큰 문제는 아닙니다. 컨테이너 내부에서 사용할 수 있는 파일 시스템은 컨테이너의 파일 시스템에 마운트되므로, 컨테이너 내부에서 이루어진 변경 사항은 컨테이너 파일 시스템 내부에만 유지됩니다. 그러나 이는 컨테이너 간 또는 호스트와 공유되는 파일이 포함된 볼륨에 영향을 미칠 수 있습니다.
컨테이너에 대해 user 네임스페이스가 활성화되면, 컨테이너의 UID는 호스트의 비권한 UID 범위로 매핑됩니다. 운영자는 Linux에서 호스트의 subuid 및 subgid 맵을 정의하고, Docker 데몬의 userns-remap 옵션을 설정하여 user 네임스페이스 리매핑을 활성화합니다. 이 매핑은 호스트의 user ID가 컨테이너 네임스페이스의 user ID와 어떻게 대응하는지를 결정합니다. 예를 들어, UID 리매핑은 컨테이너의 UID를 호스트 UID 5000부터 시작하는 범위로 매핑하도록 설정될 수 있습니다. 이 경우, 컨테이너의 UID 0은 호스트의 UID 5000에 매핑되고, 컨테이너의 UID 1은 호스트의 UID 5001에 매핑되며, 이러한 방식으로 1000개의 UID가 매핑됩니다.
Linux 관점에서 UID 5000은 비권한 user로 간주되며, 호스트 시스템 파일을 수정할 권한이 없습니다. 따라서 컨테이너에서 UID=0으로 실행되는 위험이 크게 줄어듭니다. 설령 컨테이너화된 프로세스가 호스트의 파일이나 다른 리소스를 가져온다고 해도, 이 프로세스는 매핑된 UID로 실행되며, 운영자가 명시적으로 권한을 부여하지 않는 한 해당 리소스에 대해 아무 작업도 수행할 수 없습니다.
user 네임스페이스 리매핑은 볼륨에 대한 읽기 및 쓰기 같은 파일 권한 문제를 해결하는 데 특히 유용합니다. user 네임스페이싱이 활성화된 상태에서 컨테이너 내부 프로세스가 UID 0으로 실행되는 경우, 컨테이너 간 파일 시스템을 공유하는 예제를 단계별로 살펴보겠습니다. 여기서 Docker는 다음과 같이 설정되어 있다고 가정합니다.
- 컨테이너 UID 및 GID 범위를 리매핑하기 위한 디폴트 dockremap user
- /etc/subuid 파일에 dockremap:5000:10000이라는 항목이 있으며, 이는 5000에서 시작하는 10,000개의 UID 범위를 제공합니다.
- /etc/subgid 파일에 dockremap:5000:10000이라는 항목이 있으며, 이는 5000에서 시작하는 10,000개의 GID 범위를 제공합니다.
먼저, 호스트에서 dockremap user의 user ID와 그룹 ID를 확인해봅시다. 그런 다음, 리매핑된 컨테이너의 UID 0(호스트 UID 5000)이 소유한 공유 디렉토리를 생성할 것입니다.
# id dockremap <--- Inspects user and group ID of dockermap user on host
uid=997(dockremap) gid=993(dockremap) groups=993(dockremap)
# cat /etc/subuid
dockremap:5000:10000
# cat /etc/subgid
dockremap:5000:10000
# mkdir /tmp/shared
# chown -R 5000:5000 /tmp/shared <--- Changes ownership of “shared”
directory to UID used for
remapped container UID 0
이제 컨테이너를 컨테이너의 root 유저로 실행해 보세요:
# docker run -it --rm --user root -v /tmp/shared:/shared -v /:/host alpine ash
/ # touch /host/afile <--- The /host mount is
owned by host’s UID
and GID: 0:0, so
write disallowed
touch: /host/afile: Permission denied
/ # echo "hello from $(id) in $(hostname)" >> /shared/afile
/ # exit
# back in the host shell
# ls -la /tmp/shared/afile
-rw-r--r--. 1 5000 5000 157 Apr 16 00:13 /tmp/shared/afile
# cat /tmp/shared/afile <--- /tmp/shared is owned by host’s nonprivileged
UID and GID: 5000:5000, so write allowed
hello from uid=0(root) gid=0(root) groups=0(root),1(bin),2(daemon), // UID for root
3(sys),4(adm),6(disk),10(wheel),11(floppy),20(dialout),26(tape), // in container
27(video) in d3b497ac0d34 // was 0
이 예제는 컨테이너에서 user 네임스페이스를 사용할 때 파일 시스템 접근에 미치는 영향을 보여줍니다. user 네임스페이스는 권한 있는 user로 컨테이너 간 데이터를 실행하거나 공유하는 애플리케이션의 보안을 강화하는 데 유용합니다. user 네임스페이스 리매핑은 컨테이너를 생성하거나 실행할 때 컨테이너별로 비활성화할 수 있으며, 이를 디폴트 실행 모드로 설정하기 쉽게 만듭니다. 그러나 user 네임스페이스는 SELinux나 권한 있는 컨테이너 사용과 같은 일부 선택적 기능과 호환되지 않습니다. user 네임스페이스 리매핑을 활용하면서도 사용 사례를 지원하는 Docker 구성을 설계하고 구현하려면 Docker 웹사이트의 보안 문서를 참조하세요.
6.4 Adjusting OS feature access with capabilities
Docker는 컨테이너가 개별 운영 체제 기능을 사용할 수 있는 권한을 조정할 수 있습니다. Linux에서는 이러한 기능 권한을 capabilities라고 하지만, 다른 운영 체제에서도 네이티브 지원이 확장되면 다른 백엔드 구현이 필요할 수 있습니다. 프로세스가 네트워크 소켓 열기와 같은 제한된 시스템 호출을 시도할 때마다 해당 프로세스의 capabilities가 필요한 권한에 대해 확인됩니다. 프로세스가 필요한 capability를 가지고 있다면 호출은 성공하며, 그렇지 않으면 실패합니다.
새 컨테이너를 생성할 때 Docker는 대부분의 애플리케이션을 실행하는 데 필요하고 안전한 명시적 capabilities 목록을 제외한 모든 capabilities를 제거합니다. 이는 실행 중인 프로세스를 운영 체제의 관리 기능으로부터 더욱 격리합니다. 제거된 37개의 capabilities 샘플이 아래에 나와 있으며, 그 이유를 추측할 수 있을 것입니다.
- SYS_MODULE—Insert/remove kernel modules
- SYS_RAWIO—Modify kernel memory
- SYS_NICE—Modify priority of processes
- SYS_RESOURCE—Override resource limits
- SYS_TIME—Modify the system clock
- AUDIT_CONTROL—Configure audit subsystem
- MAC_ADMIN—Configure MAC configuration
- SYSLOG—Modify kernel print behavior
- NET_ADMIN—Configure the network
- SYS_ADMIN—Catchall for administrative functions
Docker 컨테이너에 기본적으로 제공되는 capabilities 집합은 적절한 기능 감소를 제공하지만, 때로는 이 집합을 추가로 확대하거나 축소해야 할 때가 있습니다. 예를 들어, NET_RAW capability는 위험할 수 있습니다. 기본 구성보다 조금 더 신중하게 설정하려면, NET_RAW를 capabilities 목록에서 제거할 수 있습니다. 컨테이너에서 capabilities를 제거하려면 docker container create 또는 docker container run 명령에서 --cap-drop 플래그를 사용하면 됩니다. 먼저, 현재 실행 중인 컨테이너 프로세스의 기본 capabilities를 출력하여 net_raw가 포함되어 있는지 확인합니다.
docker container run --rm -u nobody \
ubuntu:24.04 \
/bin/bash -c "capsh --print | grep net_raw"
이제 컨테이너를 시작할 때 net_raw capability를 제거합니다. net_raw 문자열을 찾으려고 해도 해당 capability가 제거되었기 때문에 출력에 나타나지 않습니다.
docker container run --rm -u nobody \
--cap-drop net_raw \ <--- Drops NET_RAW capability
ubuntu:24.04 \
/bin/bash -c "capsh --print | grep net_raw"
Linux 문서에서는 capabilities가 모두 대문자로 작성되고 CAP_ 접두사가 붙은 형태로 자주 표시되지만, 이 접두사는 capability 관리 옵션에 제공할 경우 작동하지 않습니다. 최상의 결과를 위해 접두사가 없는 소문자 이름을 사용하세요.
--cap-drop 플래그와 유사하게, --cap-add 플래그를 사용하여 capabilities를 추가할 수 있습니다. 만약 특정 이유로 SYS_ADMIN capability를 추가해야 한다면, 다음과 같은 명령어를 사용할 수 있습니다.
docker container run --rm -u nobody \
ubuntu:24.04 \
/bin/bash -c "capsh --print | grep sys_admin" <--- SYS_ADMIN is not included
docker container run --rm -u nobody \
--cap-add sys_admin \ <--- Adds SYS_ADMIN
ubuntu:24.04 \
/bin/bash -c "capsh --print | grep sys_admin"
다른 컨테이너 생성 옵션과 마찬가지로, --cap-add와 --cap-drop은 각각 여러 번 지정하여 여러 capabilities를 추가하거나 제거할 수 있습니다. 이러한 플래그를 사용하면 프로세스가 적절하게 작동하는 데 필요한 기능만 수행하도록 컨테이너를 구성할 수 있습니다. 예를 들어, 네트워크 관리 데몬을 nobody 사용자로 실행하고, 호스트에서 root로 직접 실행하거나 권한 있는 컨테이너로 실행하는 대신 NET_ADMIN capability를 부여할 수 있습니다. 특정 컨테이너에서 capabilities가 추가되거나 제거되었는지 확인하려면, 컨테이너를 검사하고 출력의 .HostConfig.CapAdd 및 .HostConfig.CapDrop 멤버를 확인하면 됩니다.
6.5 Running a container with full privileges
컨테이너 내부에서 시스템 관리 작업을 수행해야 할 경우, 해당 컨테이너에 컴퓨터에 대한 privileged 접근 권한을 부여할 수 있습니다. Privileged 컨테이너는 파일 시스템 및 네트워크 격리는 유지하지만, 공유 메모리와 디바이스에 대한 완전한 접근 권한을 가지며, 전체 시스템 capabilities를 가집니다. 이를 통해 컨테이너 내부에서 Docker를 실행하는 것과 같은 흥미로운 작업을 수행할 수 있습니다.
Privileged 컨테이너의 주요 용도는 관리 작업입니다. 예를 들어, 루트 파일 시스템이 읽기 전용으로 설정된 환경, 컨테이너 외부에서 소프트웨어 설치가 금지된 환경, 또는 호스트에서 직접 셸에 접근할 수 없는 환경을 생각해 볼 수 있습니다. 만약 운영 체제를 조정(예: 로드 밸런싱)하는 프로그램을 실행해야 하고 해당 호스트에서 컨테이너를 실행할 수 있는 권한이 있다면, 이 프로그램을 privileged 컨테이너에서 실행하면 간단히 해결할 수 있습니다.
만약 privileged 컨테이너의 격리 수준 감소가 필요한 상황이라면, docker container create 또는 docker container run 명령에서 --privileged 플래그를 사용하여 이 모드를 활성화하세요.
docker container run --rm \
--privileged \
ubuntu:16.04 id <--- Checks out IDs
docker container run --rm \
--privileged \
ubuntu:16.04 capsh --print <--- Checks out Linux capabilities
docker container run --rm \
--privileged \
ubuntu:16.04 ls /dev <--- Checks out list of mounted devices
docker container run --rm \
--privileged \
ubuntu:16.04 networkctl <--- Examines network configuration
Privileged 컨테이너는 여전히 부분적으로 격리되어 있습니다. 예를 들어, 네트워크 네임스페이스(network namespace)는 여전히 적용됩니다. 이 네임스페이스를 해제해야 할 경우, --net host 옵션과 함께 사용해야 합니다.
6.6 Strengthening containers with enhanced tools
Docker는 사용이 편리하도록 합리적인 디폴트 값과 "포함된 도구 세트"를 제공하여 도입을 용이하게 하고 모범 사례를 장려합니다. 대부분의 최신 Linux 커널은 seccomp를 활성화하며, Docker의 디폴트 seccomp 프로필은 대부분의 프로그램에서 필요하지 않은 40개 이상의 커널 시스템 호출(syscalls)을 차단합니다. Docker가 빌드하는 컨테이너를 강화하려면 추가 도구를 사용할 수 있습니다. 컨테이너 보안을 강화하는 데 사용할 수 있는 도구로는 사용자 정의 seccomp 프로필, AppArmor, SELinux가 있습니다.
이러한 각 도구에 대해서는 별도의 책이 작성될 만큼 깊이가 있으며, 각각 고유한 미묘한 차이점, 이점, 그리고 필요한 기술을 요구합니다. 이 도구들을 사용하는 것은 노력 이상의 가치를 제공할 수 있습니다. 각 도구에 대한 지원은 Linux 배포판마다 다르기 때문에 일부 작업이 필요할 수 있습니다. 하지만 호스트 구성을 조정한 후에는 Docker와의 통합이 더 간단해집니다.
보안 연구
정보 보안 분야는 복잡하고 끊임없이 변화합니다. InfoSec(정보 보안) 전문가들 간의 공개 대화를 읽다 보면 종종 압도감을 느낄 수 있습니다. 이들은 종종 높은 수준의 기술을 보유하고 오랜 경험을 가진 사람들이며, 개발자나 일반 사용자와는 매우 다른 맥락을 가지고 있습니다. 공개된 InfoSec 대화에서 얻을 수 있는 가장 중요한 교훈 중 하나는 시스템 보안과 사용자 요구를 조화시키는 것이 매우 복잡하다는 점입니다.
이 분야에 처음 발을 들이는 경우, 바로 대화에 뛰어들기보다는 기사, 논문, 블로그, 책 등으로 시작하는 것이 좋습니다. 이렇게 하면 하나의 관점을 소화하고 심층적으로 이해한 후, 다른 관점으로 전환할 기회를 얻을 수 있습니다. 자신의 통찰과 의견을 형성할 시간이 생기면 이러한 대화는 훨씬 더 가치 있게 느껴질 것입니다.
단 한 편의 논문을 읽거나 단 하나의 내용을 배우는 것으로 최고의 강화된 솔루션을 구축하는 방법을 아는 것은 어렵습니다. 어떤 상황이든 시스템은 다양한 출처로부터 개선 사항을 포함하도록 진화합니다. 가장 좋은 방법은 각 도구를 개별적으로 배우는 것입니다. 어떤 도구가 깊은 이해를 요구하더라도 주저하지 마세요. 그 노력은 그 결과로 충분히 보상받을 것이며, 사용 중인 시스템을 훨씬 더 잘 이해하게 될 것입니다.
Docker는 완벽한 솔루션은 아닙니다. 일부는 이것이 보안 도구조차 아니라고 주장할 수도 있습니다. 그러나 Docker가 제공하는 개선 사항은 비용 문제로 인해 격리를 전혀 하지 않는 것보다는 훨씬 낫습니다. 여기까지 읽으셨다면, 이제 이러한 보조 주제들에 대해 더 깊이 탐구해볼 의향이 있으실지도 모릅니다.
6.6.1 Specifying additional security options
Docker는 Linux의 seccomp 및 Linux Security Modules (LSM) 기능을 구성하는 옵션을 지정하기 위해 단일 --security-opt 플래그를 제공합니다. 보안 옵션은 docker container run 및 docker container create 명령에 제공될 수 있으며, 이 플래그는 여러 값을 전달하기 위해 여러 번 설정할 수 있습니다.
Seccomp는 프로세스가 호출할 수 있는 Linux 시스템 호출을 구성합니다. Docker의 기본 seccomp 프로필은 기본적으로 모든 시스템 호출을 차단한 후, 대부분의 프로그램에서 안전하게 사용할 수 있는 260개 이상의 시스템 호출을 명시적으로 허용합니다. 44개의 차단된 시스템 호출은 일반 프로그램에 필요하지 않거나(예: 네임스페이스를 생성하는 데 사용되는 unshare) 안전하지 않거나(예: 시스템 시간을 설정하는 clock_settime) 네임스페이스화할 수 없는 경우에 해당합니다. Docker의 기본 seccomp 프로필을 변경하는 것은 권장되지 않습니다. 기본 프로필이 너무 제한적이거나 허용적일 경우, 사용자 정의 프로필을 보안 옵션으로 지정할 수 있습니다:
docker container run --rm -it \
--security-opt seccomp=<FULL_PATH_TO_PROFILE> \
ubuntu:24.04 sh
<FULL_PATH_TO_PROFILE>는 컨테이너에서 허용할 시스템 호출을 정의하는 seccomp 프로필의 전체 경로입니다. GitHub의 Moby 프로젝트는 Docker의 기본 seccomp 프로필을 profiles/seccomp/default.json에 제공하며, 사용자 정의 프로필의 시작점으로 사용할 수 있습니다. unconfined라는 특수 값을 사용하여 컨테이너에 대해 seccomp 사용을 비활성화할 수 있습니다.
Linux Security Modules는 운영 체제와 보안 제공자 간의 인터페이스 계층 역할을 하도록 Linux에서 채택된 프레임워크입니다. AppArmor와 SELinux는 LSM 제공자로, 둘 다 **Mandatory Access Control (MAC)**을 제공합니다. MAC은 시스템이 접근 규칙을 정의하며, 표준 Linux의 Discretionary Access Control (DAC)(파일 소유자가 접근 규칙을 정의)을 대체합니다.
LSM 보안 옵션 값은 다음 7가지 형식 중 하나로 지정됩니다:
- 컨테이너가 시작된 후 새로운 권한을 얻지 못하도록 방지하려면, no-new-privileges를 사용합니다.
- SELinux 사용자 레이블을 설정하려면, label=user:<USERNAME> 형식을 사용하며, <USERNAME>은 레이블에 사용할 사용자 이름입니다.
- SELinux 역할 레이블을 설정하려면, label=role:<ROLE> 형식을 사용하며, <ROLE>은 컨테이너 프로세스에 적용할 역할 이름입니다.
- SELinux 타입 레이블을 설정하려면, label=type:<TYPE> 형식을 사용하며, <TYPE>은 컨테이너 프로세스의 타입 이름입니다.
- SELinux 레벨 레이블을 설정하려면, label=level:<LEVEL> 형식을 사용하며, <LEVEL>은 컨테이너 프로세스가 실행되어야 하는 레벨입니다. 레벨은 low-high 쌍으로 지정되며, low 레벨만 지정할 경우 SELinux는 이를 단일 레벨로 해석합니다.
- 컨테이너에 대한 SELinux 레이블 격리를 비활성화하려면, label=disable 형식을 사용합니다.
- 컨테이너에 AppArmor 프로파일을 적용하려면, apparmor=<PROFILE> 형식을 사용하며, <PROFILE>은 사용할 AppArmor 프로파일의 이름입니다.
SELinux는 레이블링 시스템입니다. 컨텍스트(context)라고 불리는 레이블 세트가 모든 파일과 시스템 객체에 적용됩니다. 유사한 레이블 세트가 모든 사용자와 프로세스에도 적용됩니다. 실행 중에 프로세스가 파일이나 시스템 리소스와 상호작용하려고 하면, 레이블 세트는 허용된 규칙 세트와 비교됩니다. 이 평가 결과에 따라 상호작용이 허용되거나 차단됩니다.
마지막 옵션은 AppArmor 프로파일을 설정합니다. AppArmor는 SELinux를 대체하는 경우가 많으며, 레이블 대신 파일 경로를 사용하고, 애플리케이션 동작을 관찰하여 프로파일을 수동으로 생성할 수 있는 트레이닝 모드를 제공합니다. 이러한 차이점은 AppArmor가 채택 및 유지 관리하기 더 쉽다는 이유로 자주 언급됩니다.
애플리케이션에 맞춘 사용자 정의 프로파일을 생성하는 무료 및 상업용 도구가 제공됩니다. 이러한 도구는 테스트 및 프로덕션 환경에서 실제 프로그램 동작 정보를 활용하여 작동하는 프로파일을 생성하도록 돕습니다.
6.7 Building use-case-appropriate containers
컨테이너는 다양한 방식과 이유로 사용될 수 있는 횡단 관심사입니다. 따라서 Docker를 사용해 자신의 목적에 맞는 컨테이너를 빌드할 때, 실행할 소프트웨어에 적합한 방식으로 시간을 들여 설정하는 것이 중요합니다.
가장 안전한 방법은 가능한 한 가장 격리된 컨테이너를 빌드한 다음, 이러한 제한을 완화할 이유를 정당화하는 것입니다. 그러나 현실적으로 사람들은 예방적이기보다는 반응적인 경우가 많습니다. 이런 이유로 Docker의 기본 컨테이너 구성은 사용자 생산성을 저해하지 않으면서도 합리적인 기본값을 제공하는 절충안을 제공한다고 볼 수 있습니다.
Docker 컨테이너는 기본적으로 가장 격리된 상태로 설정되지 않습니다. Docker는 사용자가 이러한 기본값을 강화하도록 요구하지 않습니다. 원한다면 실사용 환경에서 비합리적인 설정을 할 수도 있습니다. 이러한 점은 Docker를 부담이 아닌 도구로 느껴지게 하고, 사람들이 일반적으로 사용하고 싶어 하는 것으로 만듭니다. 그러나 실사용 환경에서 비합리적인 설정을 하지 않으려는 사용자들을 위해, Docker는 컨테이너 격리를 강화할 수 있는 간단한 인터페이스를 제공합니다.
6.7.1 Applications
애플리케이션은 우리가 컴퓨터를 사용하는 가장 중요한 이유입니다. 대부분의 애플리케이션은 다른 사람들이 작성한 프로그램이며, 잠재적으로 악성 데이터를 처리합니다. 웹 브라우저를 예로 들어봅시다.
웹 브라우저는 거의 모든 컴퓨터에 설치된 애플리케이션의 한 종류입니다. 이는 웹 페이지, 이미지, 스크립트, 임베디드 비디오, 플래시 문서, 자바 애플리케이션 등 다양한 콘텐츠와 상호작용합니다. 이 모든 콘텐츠를 여러분이 직접 생성한 것은 아닐 것입니다. 그리고 대부분의 사람들은 웹 브라우저 프로젝트에 기여한 적도 없습니다. 그렇다면 어떻게 웹 브라우저가 이러한 콘텐츠를 올바르게 처리한다고 신뢰할 수 있을까요?
조금 대범한 독자라면 이런 문제를 무시할 수도 있을 것입니다. 결국, 최악의 경우 어떤 일이 벌어질 수 있을까요? 그러나 공격자가 웹 브라우저(또는 다른 애플리케이션)를 장악한다면, 해당 애플리케이션의 모든 기능과 그것이 실행되는 사용자의 권한을 얻게 됩니다. 이로 인해 컴퓨터가 손상되거나, 파일이 삭제되거나, 다른 악성 소프트웨어가 설치되거나, 심지어는 여러분의 컴퓨터를 통해 다른 컴퓨터를 공격하는 일이 벌어질 수 있습니다. 따라서 이런 문제를 무시하는 것은 좋은 선택이 아닙니다. 그렇다면 이러한 위험을 감수해야 할 때, 어떻게 자신을 보호할 수 있을까요?
가장 좋은 접근 방식은 프로그램 실행의 위험을 격리하는 것입니다.
첫째, 애플리케이션이 제한된 권한의 사용자로 실행되도록 설정하십시오. 이렇게 하면 문제가 발생하더라도 컴퓨터의 파일을 변경할 수 없습니다.
둘째, 브라우저의 시스템 기능을 제한하십시오. 이를 통해 시스템 구성을 더 안전하게 만들 수 있습니다.
셋째, 애플리케이션이 사용할 수 있는 CPU와 메모리 양을 제한하십시오. 제한을 두면 시스템이 응답성을 유지할 수 있는 리소스를 예약할 수 있습니다.
마지막으로, 액세스할 수 있는 장치를 명확히 화이트리스트에 추가하는 것이 좋습니다. 이렇게 하면 웹캠, USB와 같은 장치를 감시하는 것을 방지할 수 있습니다.
6.7.2 High-level system services
고수준 시스템 서비스는 애플리케이션과는 조금 다릅니다. 운영 체제의 일부는 아니지만, 컴퓨터는 이러한 서비스가 시작되고 계속 실행되도록 보장합니다. 이러한 도구는 일반적으로 운영 체제 외부에서 애플리케이션과 함께 작동하지만, 올바르게 작동하기 위해 운영 체제에 대한 특권 액세스가 필요한 경우가 많습니다. 이들은 시스템에서 사용자 및 다른 소프트웨어에 중요한 기능을 제공합니다. 예로는 cron, syslogd, dnsmasq, sshd, docker 등이 있습니다.
이 도구들 중 일부가 익숙하지 않더라도 괜찮습니다. 이들은 시스템 로그를 유지하거나, 예약된 명령을 실행하거나, 네트워크를 통해 시스템에 안전한 셸을 제공하며, Docker는 컨테이너를 관리하는 역할을 합니다.
서비스를 root로 실행하는 것이 일반적이지만, 대부분의 서비스는 전체 특권 액세스가 필요하지 않습니다. 서비스를 컨테이너화하고 필요한 특정 기능에 맞게 액세스를 조정하기 위해 capabilities를 사용하는 것을 고려하십시오.
6.7.3 Low-level system services
저수준 서비스는 디바이스나 시스템의 네트워크 스택과 같은 것을 제어합니다. 이들은 제공하는 시스템 구성 요소(예: 방화벽 소프트웨어는 네트워크 스택에 대한 관리자 액세스가 필요함)에 대한 특권 액세스가 필요합니다.
이러한 서비스가 컨테이너 내에서 실행되는 경우는 드뭅니다. 파일 시스템 관리, 디바이스 관리, 네트워크 관리와 같은 작업은 핵심 호스트의 문제입니다. 대부분의 컨테이너에서 실행되는 소프트웨어는 이식 가능성을 기대하기 때문에, 이러한 기계 특정 작업은 일반적인 컨테이너 사용 사례에 적합하지 않습니다.
가장 좋은 예외는 단기 실행 구성 컨테이너입니다. 예를 들어, 모든 배포가 Docker 이미지와 컨테이너를 통해 이루어지는 환경에서는 네트워크 스택 변경을 소프트웨어 배포와 동일한 방식으로 푸시할 수 있습니다. 이 경우 구성된 이미지를 호스트에 푸시하고 특권 컨테이너를 사용하여 변경을 수행할 수 있습니다. 이 경우 위험은 감소합니다. 이유는 푸시된 구성을 작성한 주체가 본인이며, 컨테이너가 장기 실행되지 않고, 이러한 변경은 간단하게 감사할 수 있기 때문입니다.
'Docker' 카테고리의 다른 글
| 8 Building images automatically with Dockerfiles (0) | 2024.04.04 |
|---|---|
| 7 Packaging software in images (0) | 2024.04.03 |
| 5 Single-host networking (0) | 2024.03.29 |
| 4. Working with storage and volumes (0) | 2024.03.26 |
| 3. Software installation simplified (0) | 2024.03.25 |